1 Introduction
1.1 Fully Connected Layer (MLP)의 문제점
Affine Layer는 인접하는 Layers의 nodes가 모두 연결되고 출력의 수가 임의로 정해지는 특징을 갖는데 이 때 data shape가 무시가 되는 단점이 있다. 이미지 데이터는 보통 (weight, height, color channel) 형태의 shape를 갖지만 MLP에서 이 3차원 구조가 1차원으로 flatten된다. 다시 말해서, 3차원의 이미지 pixels이라는 여러 독립 변수의 위치적 상관성이 1차원화 되면서 무시가 된다.
많은 일반 머신러닝 모델이나 통계 분석 모델은 독립 변수가 독립이라는 가정이 고려되어야 하지만 이미지의 독립 변수들이 서로 독립이 아니다. 픽셀값은 그 위치에 따라서 서로 상관성이 존재한다. 초기엔 독립 변수인 픽셀을 일렬로 늘어뜨려 input으로 사용했지만 위치 기반 픽셀의 상관성 정도를 자세히 반영하진 못했다. 이를 보완하기 위해 CNN에서는 region feature가 고안됐다. 이처럼, CNN은 이미지 인식 분야에서 독보적인 영역을 갖고 있다.
1.2 Region Feature
Region Feature 또는 Graphic Feature라고도 한다. 픽셀의 지역 정보를 학습할 수 있는 신경망 구조가 CNN이다.
2 CNN
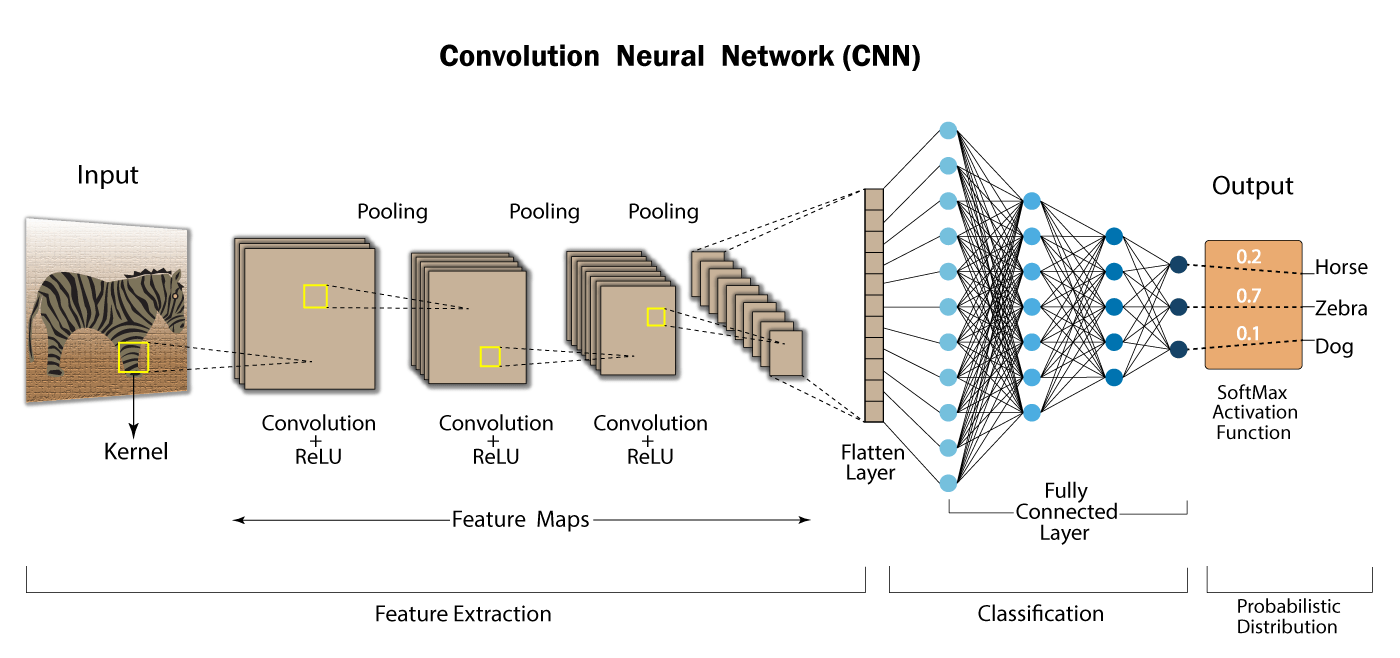
Convolutional Neural Network (CNN)은 합성곱(convolution)으로 이루어진 인공신경망으로 Region Feature를 학습하기 위한 모형이다. CNN은
- region feature를 추출하기 위한 convolution layer,
- activation function,
- feature dimension을 위한 pooling layer
- fully connected layer (Multi Layer Perceptron (MLP) or Affine Transformation)
- Softmax function
로 구성되어 있다 (See 그림 1).
2.1 Convolution Layer (Conv)
kernel 또는 filter라고 불리는 특징 추출기(Feature detector)를 사용하여 데이터의 특징을 추출하는 CNN 모델의 핵심 부분이다. kernel 를 정의해 입력 층의 이미지의 feature를 추출한다. kernel는 region feature의 크기와 weight을 정의하게 된다. 예를 들어, kernel을 (3x3)으로 정하면 9칸에 가중치를 설정하여 이미지 픽셀값 (a part of input feature map)과 kernel의 weight의 선형결합으로 conv layer를 구성하는 하나의 값을 얻어낸다 (See 그림 1 의 노란색 사각형).
convolution layer의 input/output은 보통 feature map이라고 부르며 input data를 input feature map, output data를 output feature map로 부르기도 한다. 즉, feature map 과 input/output data는 같은 의미로 사용되고 feature map = input data + kernel (= receptive field = filter)로 구성된다.
2.1.1 Convolution Operation
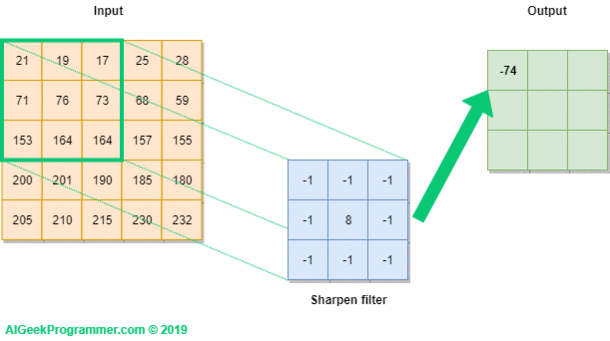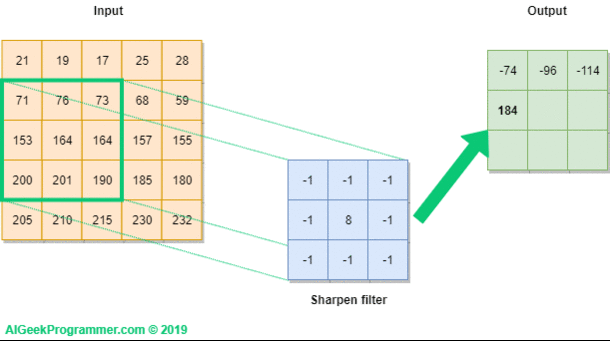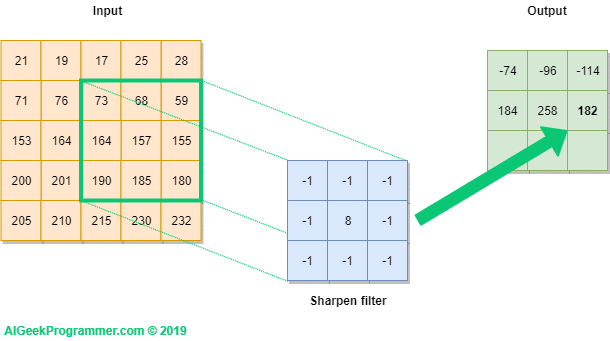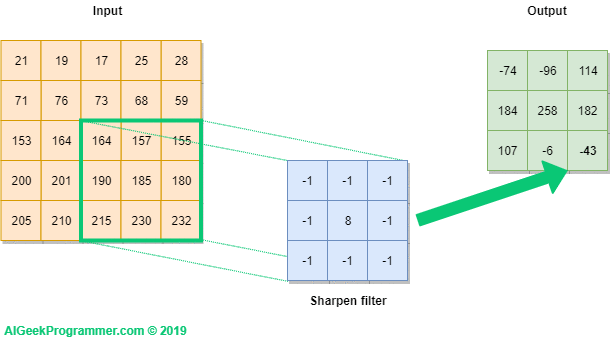
Convolution Operation (합성곱 연산)은 filter operation (filter 연산)이라고도 불린다. 그림 2 을 보면 입력 데이터 (이미지의 pixels)와 filter의 가중치가 element-wise 별로 곱해져 더해진다. 이 연산을 fused-multiply-add (FMA) or multiply-accumulate operation 라고도 부른다. 예를 들어, input data의 matrix([[4,9,2],[5,6,2],[2,4,5]])와 filter1 의 matrix([[1,0,-1],[1,0,-1],[1,0,-1]]) 가 곱해지고 더해져 matrix([[4,0,-2],[5,0,-2],[2,0,-5]])의 결과가 Conv Layer의 output data의 한 칸을 구성하게 된다.
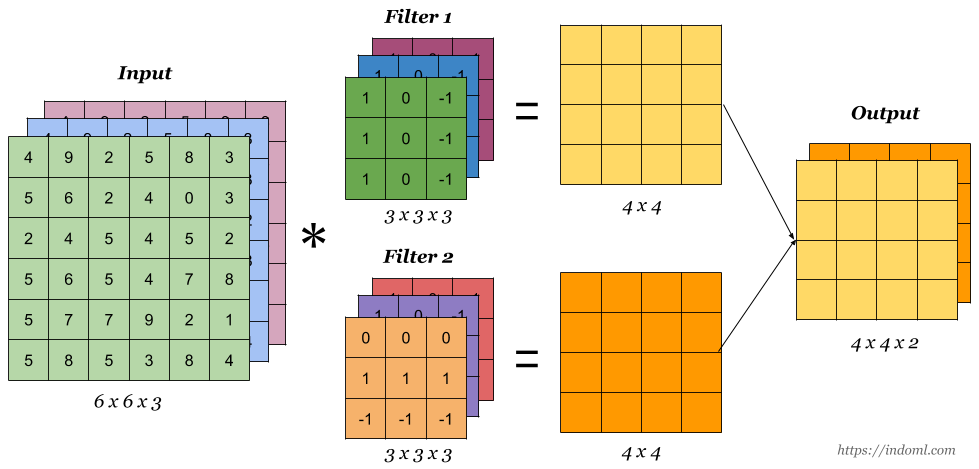
이렇게, 2차원 입력에 대한 convolution (conv) operation은 그림 3 과 같이 동작한다. Sharpen filter라고 쓰여진 3x3 행렬은 kernel로서 입력 데이터의 특징을 추출하는데, 입력 데이터의 전체를 보는 것이 아닌 kernel size 만큼의 일부분만을 보며 특징을 추출한다. feature map은 kernel의 개수만큼 생성되는데 일반적으로 다양한 특징을 추출하기 위해 하나의 conv layer에서 여러개의 kernel을 사용한다. kernel size에 정해진 규칙은 없으나 주로 3*3 많이 사용하며 대게 conv layer마다 다른 kernel size를 적용한다. Fully connected layer에서의 weight는 CNN에서 filter의 weight과 대응되고 CNN에서의 bias는 항상 scalar로 주어진다.
2.1.2 합성곱 연산을 위한 설정 사항
- padding : 입력 데이터의 테두리를 0으로 채워 데이터의 크기를 늘려준다
- 왜 padding을 사용하는가? padding이 없을 경우 합성곱은 입력 데이터의 1행 1열부터 시작된다. 그런데 합성곱은 입력 데이터에서 kernel size만큼의 영역을 하나로 축소하여 특징을 추출하기 때문에 이 경우 입력 데이터의 가장자리, edge 부분의 특징을 추출하기 어렵다. edge의 특징까지 추출하고자 하면 적어도 0행 0열부터 kernel을 적용해야 하는데 허공에서 element-wise 계산을 할 수 없으니 0을 추가해준다. 다시 말해서, padding은 output data size를 조정할 목적으로 사용된다.

- 왜 padding을 사용하는가? padding이 없을 경우 합성곱은 입력 데이터의 1행 1열부터 시작된다. 그런데 합성곱은 입력 데이터에서 kernel size만큼의 영역을 하나로 축소하여 특징을 추출하기 때문에 이 경우 입력 데이터의 가장자리, edge 부분의 특징을 추출하기 어렵다. edge의 특징까지 추출하고자 하면 적어도 0행 0열부터 kernel을 적용해야 하는데 허공에서 element-wise 계산을 할 수 없으니 0을 추가해준다. 다시 말해서, padding은 output data size를 조정할 목적으로 사용된다.
- stride : kernel이 얼만큼씩 이동하면서 합성곱 계산을 할 것인지를 의미한다.
- stride를 키우게 되면 output data size가 작아지기 때문에 일반적으로 한 칸씩 이동한다.
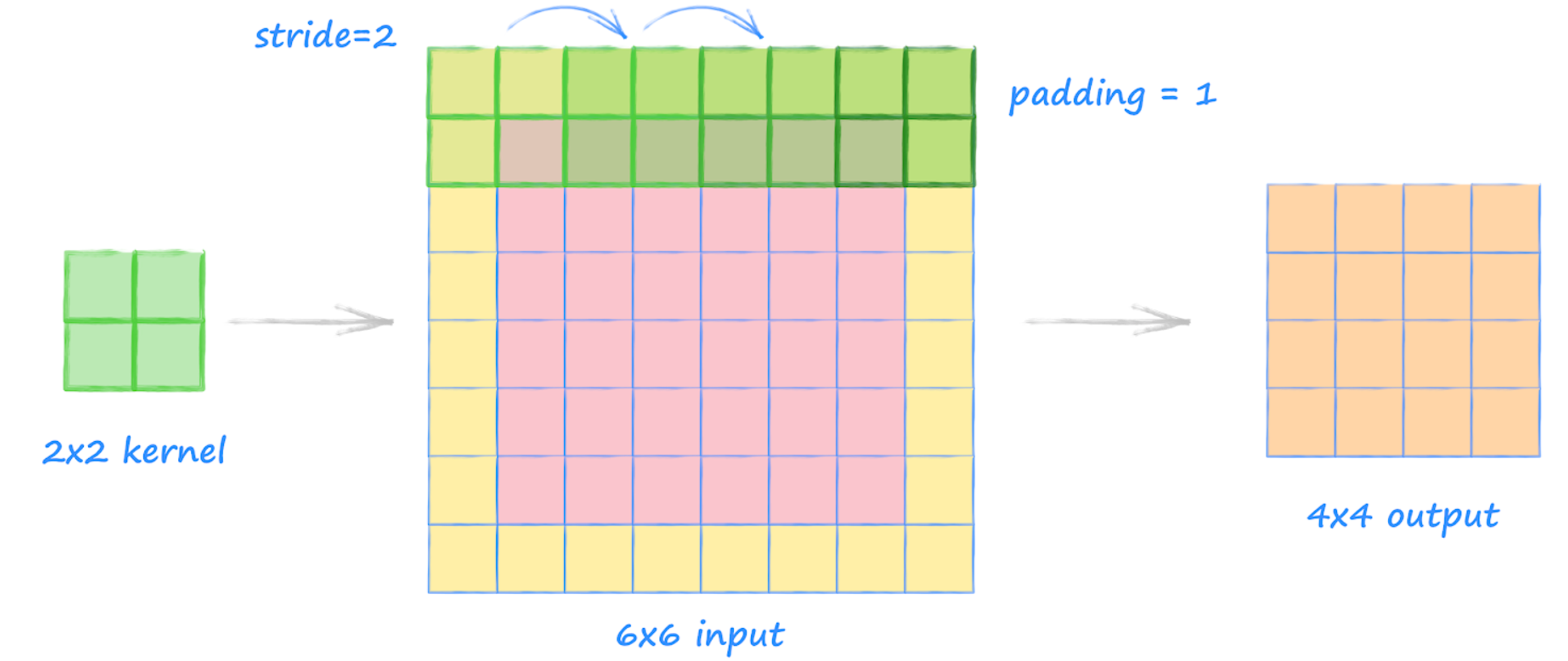
- stride를 키우게 되면 output data size가 작아지기 때문에 일반적으로 한 칸씩 이동한다.
- weight sharing:
- kernel size : kernel의 행과 열 개수
- 사이즈가 작을수록 국소 단위의 특징을 추출한다.
- kernel 개수 또는 channel 개수 : 몇 개의 feature map을 추출하고 싶은지에 따라 kernel 개수를 정한다.
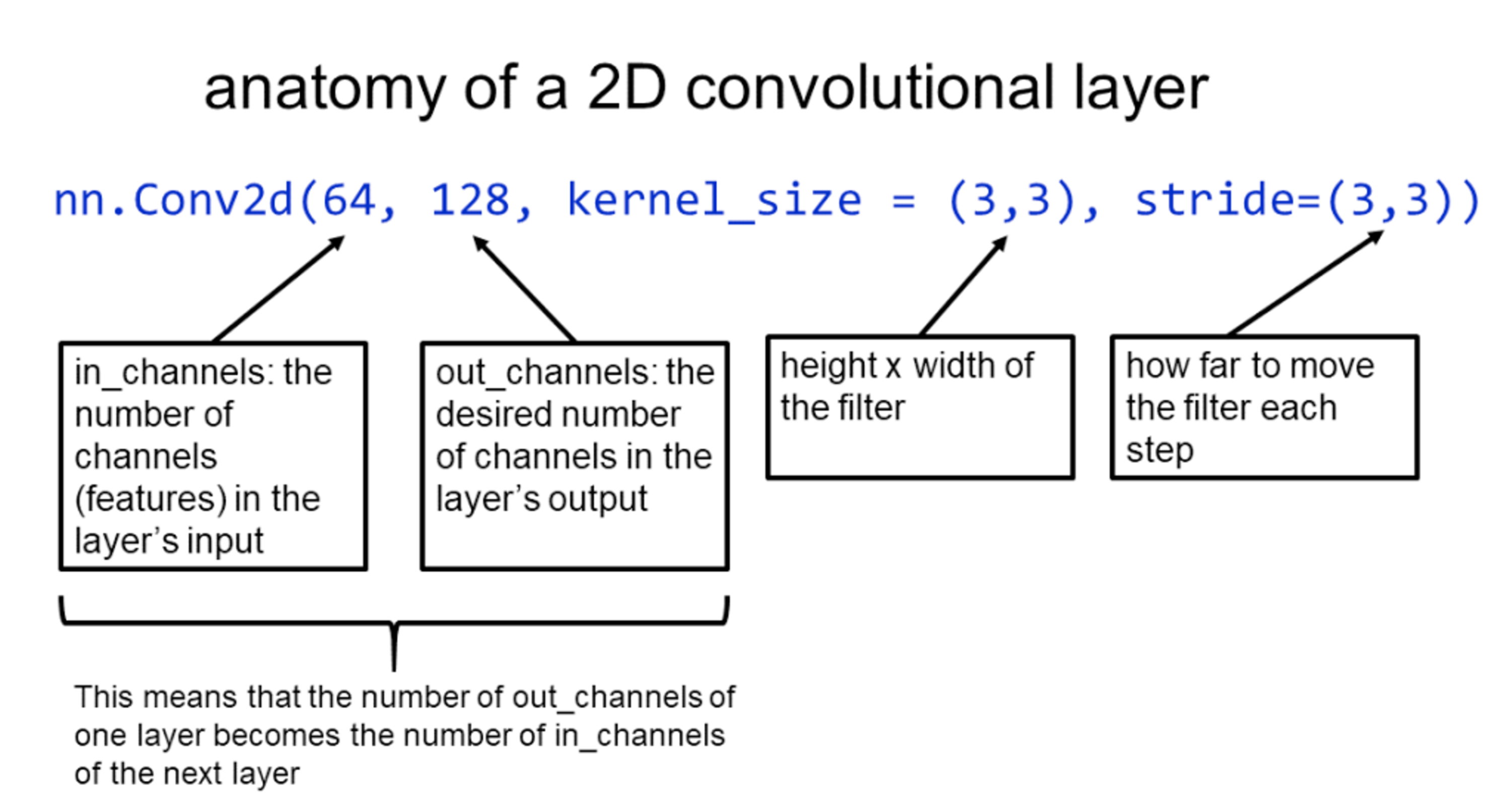
- 이미지 데이터에서의 channel 예시
- 고양이 이미지와 같이 컬러 이미지 데이터는 하나의 이미지에 대해 Red, Green, Blue (RGB) 3개의 색상으로 이루어져 있다
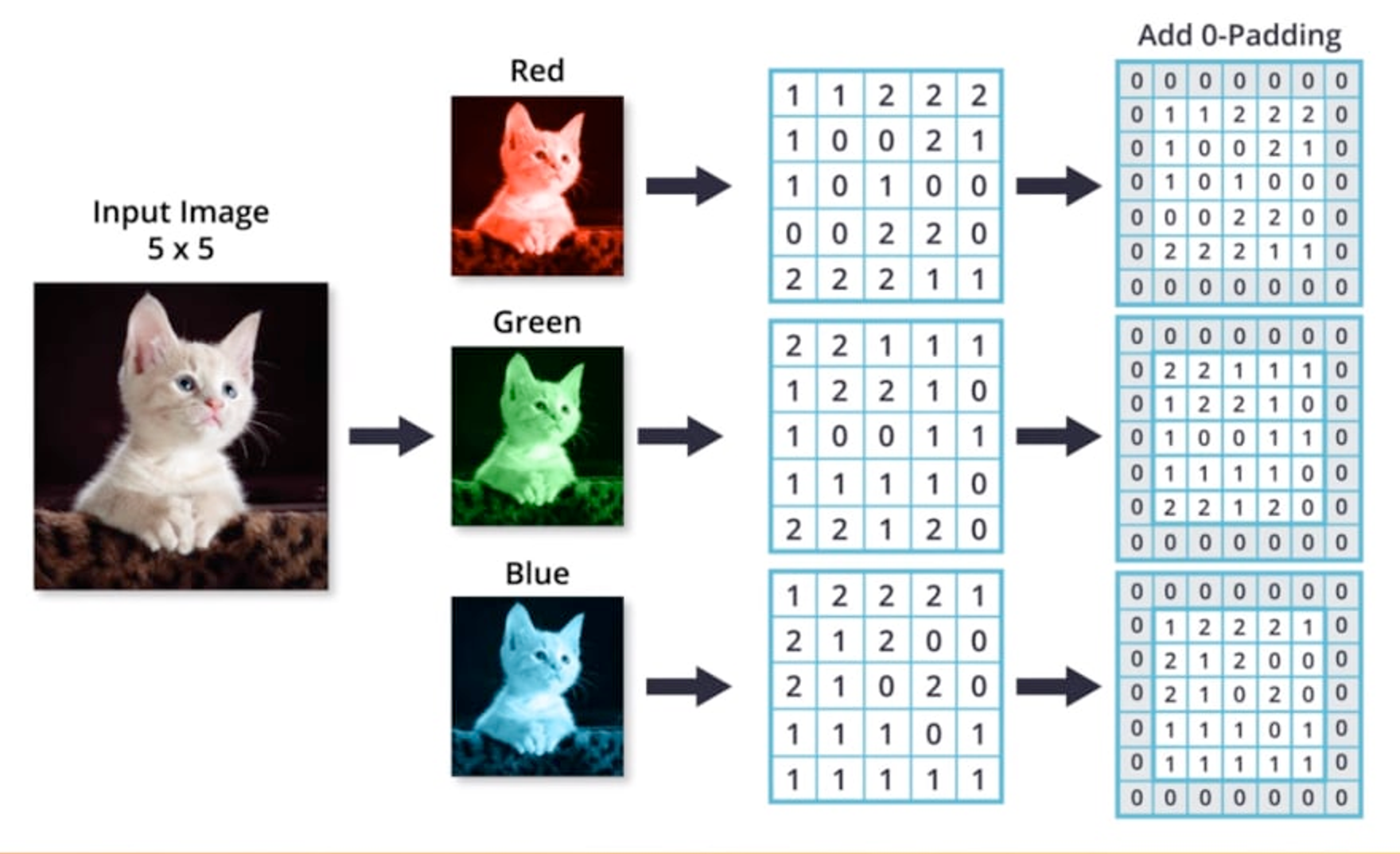
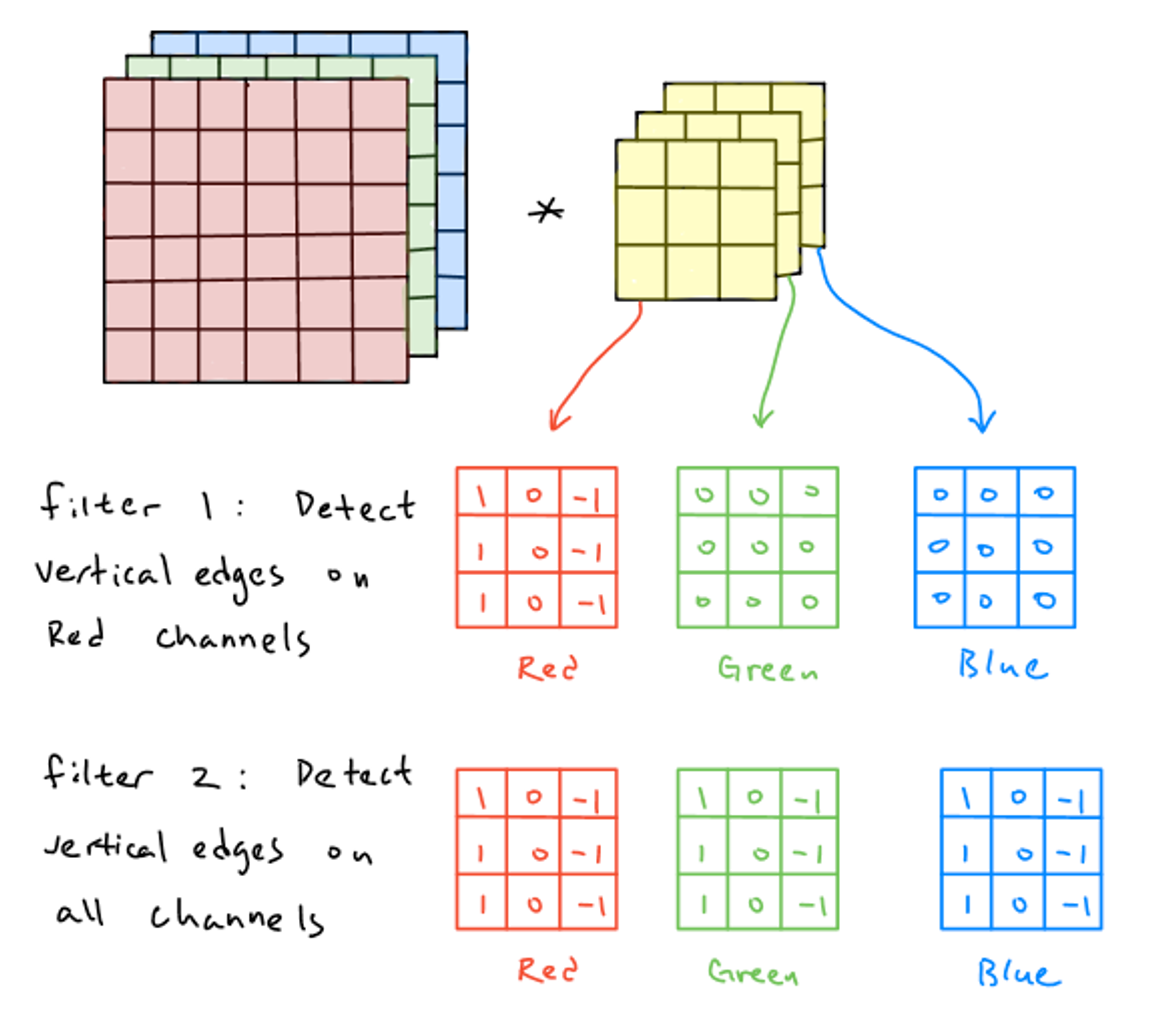
- 고양이 이미지와 같이 컬러 이미지 데이터는 하나의 이미지에 대해 Red, Green, Blue (RGB) 3개의 색상으로 이루어져 있다
2.1.3 feature map의 shape 계산 방법
feature map은 다음 레이어의 입력 데이터가 되기 때문에 feature map의 shape을 계산할 수 있어야한다.
2.1.3.1 2 Dimension Input Data Size
다음과 같이 output data size계산을 위한 notation을 정의할 때,
- input data size : \((H,W)\)
- filter size : \((FH, FW)\)
- output data size : \((OH, OW)\)
- padding : \(P\) (width number)
- stride : \(S\)
- a function to make the calculation result an integer
- floor function : \(\lfloor \text{ } \rfloor\)
- ceiling : \(\lceil \text{ } \rceil\)
- rounding to the nearest integer: \(\lfloor \text{ } \rceil\)
\[ \begin{aligned} OH=&\lfloor\frac{H+2P-FH}{S}+1\rfloor\\ OW=&\lfloor\frac{W+2P-FW}{S}+1\rfloor \end{aligned} \]
의 관계식을 따르게 된다.
- 예시1- input size: (4x4), P:1, S:1, filter size : (3x3)일 때, \((OH,OW)=(4,4)\)
- 예시2- input size: (7x7), P:0, S:2, filter size : (3x3)일 때, \((OH,OW)=(3,3)\)
- 예시3- input size: (28x31), P:2, S:3, filter size : (5x5)일 때, \((OH,OW)=(10,11)\)
2.1.3.2 3 Dimension Input Data Size
길이 또는 채널 방향으로 feature map이 늘어나기 때문에 그 결과는 그림 2 과 같이 나온다. 반드시 input data의 channel 수와 output data channel수가 같아야한다. 채널이 3개면 filter 당 3장의 feature map이 나오게 된다. filter의 종류의 수 weight의 종류의 수로 output data의 길이를 늘리려면 (즉, 다수의 채널로 만드려면) filter의 수 (=weight의 종류)를 늘리면 된다. FN: Flter Number일 때 filter의 가중치 데이터 크기는 (output data channel, input data channel, height, width)로 표현한다. Bias는 \((FN,1,1)\) 로 표현하여 채널 하나에 값 하나씩 할당되게 디자인한다. Output data size는 \((FN,OH,OW)\) 로 표현된다.
참고) \[ (FN,1,1) + (FN,OH,OW) \overset{\text{broadcasting}} \rightarrow (FN,OH,OW) \]
- 예시- 채널=3, (FH,FW)=(4,4), \(FN=20\) 이면 \((20,3,4,4)\) 로 표현
2.2 Batch Processing
데이터를 (데이터수, 채널 수, 높이, 너비) \(= (N,C,H,W)\) 순으로 저장하여 처리하여 NN에 4차원 데이터가 하나가 흐를 때마다 데이터 N개의 합성곱 연산이 발생한다. N번의 처리를 한번에 수행한다.