1 계층적 에이전트 팀
이 튜토리얼에서는 계층적 에이전트 팀을 구성하는 방법을 살펴봅니다.
단일 에이전트나 단일 수준의 감독자(supervisor)로는 대응하기 힘든 복잡한 작업을 계층적 구조를 통해 분할하고, 각각의 하위 수준 감독자(supervisor)가 해당 영역에 특화된 작업자(Worker) 에이전트를 관리하는 방식을 구현합니다.
이러한 계층적 접근 방식은 작업자가 너무 많아질 경우나, 단일 작업자가 처리하기 힘든 복잡한 작업을 효율적으로 해결하는 데 도움이 됩니다.
본 예제는 AutoGen 논문의 아이디어를 LangGraph를 통해 구현한 사례로, 웹 연구와 문서 작성이라는 두 가지 하위 작업을 서로 다른 팀으로 구성하고, 상위 및 중간 수준의 감독자를 통해 전체 프로세스를 관리하는 방법을 제시합니다.
왜 계층적 에이전트 팀인가?
이전 Supervisor 예제에서는 하나의 supervisor node가 여러 작업자 노드에게 작업을 할당하고 결과를 취합하는 과정을 살펴보았습니다. 이 방식은 간단한 경우에 효율적입니다. 그러나 다음과 같은 상황에서는 계층적 구조가 필요할 수 있습니다.
- 작업 복잡성 증가: 단일 supervisor로는 한 번에 처리할 수 없는 다양한 하위 영역의 전문 지식이 필요할 수 있습니다.
- 작업자 수 증가: 많은 수의 작업자를 관리할 때, 단일 supervisor가 모든 작업자에게 직접 명령을 내리면 관리 부담이 커집니다.
이러한 상황에서 상위 수준의 supervisor는 하위 수준의 sub-supervisor 들에게 작업을 할당하고, 각 sub-supervisor 는 해당 작업을 전문화된 작업자 팀에 재할당하는 계층적 구조를 구성할 수 있습니다.
이 튜토리얼에서 다룰 내용
- 도구 생성: 웹 연구(Web Research) 및 문서 작성(Documentation)을 위한 에이전트 도구 정의
- 에이전트 팀 정의: 연구 팀 및 문서 작성 팀을 계층적으로 정의하고 구성
- 계층 추가: 상위 수준 그래프와 중간 수준 감독자를 통해 전체 작업을 계층적으로 조정
- 결합: 모든 요소를 통합하여 최종적인 계층적 에이전트 팀 구축
참고
- AutoGen 논문: Enabling Next-Gen LLM Applications via Multi-Agent Conversation (Wu et al.)
- LangGraph - Multi-Agent 개념
1.1 환경 설정
1.2 도구 생성
각 팀은 하나 이상의 에이전트로 구성되며, 각 에이전트는 하나 이상의 도구를 갖추게 됩니다. 아래에서는 다양한 팀에서 사용할 모든 도구를 정의합니다.
먼저 연구 팀을 살펴보겠습니다.
ResearchTeam 도구
ResearchTeam은 웹에서 정보를 찾기 위해 검색 엔진과 URL 스크래퍼를 사용할 수 있습니다. ResearchTeam의 성능을 향상시키기 위해 추가 기능을 아래에 자유롭게 추가할 수 있습니다.
from typing import List
from langchain_community.document_loaders import WebBaseLoader
from langchain_teddynote.tools.tavily import TavilySearch
from langchain_core.tools import tool
# 검색 도구 정의(TavilySearch)
tavily_tool = TavilySearch(max_results=5)
# 웹 페이지에서 세부 정보를 스크래핑하기 위한 도구 정의
@tool
def scrape_webpages(urls: List[str]) -> str:
"""Use requests and bs4 to scrape the provided web pages for detailed information."""
# 주어진 URL 목록을 사용하여 웹 페이지 로드
loader = WebBaseLoader(
web_path=urls,
header_template={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36",
},
)
docs = loader.load()
# 로드된 문서의 제목과 내용을 포함한 문자열 생성
return "\n\n".join(
[
f'<Document name="{doc.metadata.get("title", "")}">\n{doc.page_content}\n</Document>'
for doc in docs
]
)문서 작성 팀 도구
다음으로, 문서 작성 팀이 사용할 도구(파일 접근 도구)를 정의합니다.
이 도구는 에이전트가 파일 시스템에 접근할 수 있도록 하며, 이는 안전하지 않을 수 있습니다. 따라서, 사용에 주의가 필요합니다.
from pathlib import Path
from typing import Dict, Optional, List
from typing_extensions import Annotated
# 임시 디렉토리 생성 및 작업 디렉토리 설정
WORKING_DIRECTORY = Path("./tmp")
# tmp 폴더가 없으면 생성
WORKING_DIRECTORY.mkdir(exist_ok=True)
# 아웃라인 생성 및 파일로 저장
@tool
def create_outline(
points: Annotated[List[str], "List of main points or sections."],
file_name: Annotated[str, "File path to save the outline."],
) -> Annotated[str, "Path of the saved outline file."]:
"""Create and save an outline."""
# 주어진 파일 이름으로 아웃라인을 저장
with (WORKING_DIRECTORY / file_name).open("w") as file:
for i, point in enumerate(points):
file.write(f"{i + 1}. {point}\n")
return f"Outline saved to {file_name}"
# 문서 읽기
@tool
def read_document(
file_name: Annotated[str, "File path to read the document."],
start: Annotated[Optional[int], "The start line. Default is 0"] = None,
end: Annotated[Optional[int], "The end line. Default is None"] = None,
) -> str:
"""Read the specified document."""
# 주어진 파일 이름으로 문서 읽기
with (WORKING_DIRECTORY / file_name).open("r") as file:
lines = file.readlines()
# 시작 줄이 지정되지 않은 경우 기본값 설정
if start is not None:
start = 0
return "\n".join(lines[start:end])
# 문서 쓰기 및 저장
@tool
def write_document(
content: Annotated[str, "Text content to be written into the document."],
file_name: Annotated[str, "File path to save the document."],
) -> Annotated[str, "Path of the saved document file."]:
"""Create and save a text document."""
# 주어진 파일 이름으로 문서 저장
with (WORKING_DIRECTORY / file_name).open("w") as file:
file.write(content)
return f"Document saved to {file_name}"
# 문서 편집
@tool
def edit_document(
file_name: Annotated[str, "File path of the document to be edited."],
inserts: Annotated[
Dict[int, str],
"Dictionary where key is the line number (1-indexed) and value is the text to be inserted at that line.",
],
) -> Annotated[str, "File path of the edited document."]:
"""Edit a document by inserting text at specific line numbers."""
# 주어진 파일 이름으로 문서 읽기
with (WORKING_DIRECTORY / file_name).open("r") as file:
lines = file.readlines()
# 삽입할 텍스트를 정렬하여 처리
sorted_inserts = sorted(inserts.items())
# 지정된 줄 번호에 텍스트 삽입
for line_number, text in sorted_inserts:
if 1 <= line_number <= len(lines) + 1:
lines.insert(line_number - 1, text + "\n")
else:
return f"Error: Line number {line_number} is out of range."
# 편집된 문서를 파일에 저장
with (WORKING_DIRECTORY / file_name).open("w") as file:
file.writelines(lines)
return f"Document edited and saved to {file_name}"다음은 코드 실행 도구인 PythonREPLTool 을 정의합니다.
1.3 다중 에이전트 생성을 위한 유틸리티 함수 정의
다음은 작업을 간결하게 수행하기 위한 몇 가지 유틸리티 함수를 생성하는 방법입니다.
이때 이전 튜토리얼에서 다룬 functools.partial 함수를 사용하여 에이전트 노드를 생성합니다.
worker agent생성.sub-graph의supervisor생성.
from langgraph.graph import START, END
from langchain_core.messages import HumanMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# 에이전트 팩토리 클래스
class AgentFactory:
def __init__(self, model_name):
self.llm = ChatOpenAI(model=model_name, temperature=0)
def create_agent_node(self, agent, name: str):
# 노드 생성 함수
def agent_node(state):
result = agent.invoke(state)
return {
"messages": [
HumanMessage(content=result["messages"][-1].content, name=name)
]
}
return agent_node
# LLM 초기화
llm = ChatOpenAI(model=MODEL_NAME, temperature=0)
# Agent Factory 인스턴스 생성
agent_factory = AgentFactory(MODEL_NAME)아래는 AgentFactory 를 사용하여 에이전트 노드를 생성하는 예시입니다.
예시에서는 검색 에이전트를 생성하는 방법을 살펴보겠습니다.
# 에이전트 정의
search_agent = create_react_agent(llm, tools=[tavily_tool])
# 에이전트 노드 생성
search_node = agent_factory.create_agent_node(search_agent, name="Searcher")다음은 팀 감독자(Team Supervisor)를 생성하는 함수입니다.
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from typing import Literal
def create_team_supervisor(model_name, system_prompt, members) -> str:
# 다음 작업자 선택 옵션 목록 정의
options_for_next = ["FINISH"] + members
# 작업자 선택 응답 모델 정의: 다음 작업자를 선택하거나 작업 완료를 나타냄
class RouteResponse(BaseModel):
next: Literal[*options_for_next]
# ChatPromptTemplate 생성
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"Given the conversation above, who should act next? "
"Or should we FINISH? Select one of: {options}",
),
]
).partial(options=str(options_for_next))
# LLM 초기화
llm = ChatOpenAI(model=model_name, temperature=0)
# 프롬프트와 LLM을 결합하여 체인 구성
supervisor_chain = prompt | llm.with_structured_output(RouteResponse)
return supervisor_chain1.4 에이전트 팀 정의
연구 팀(Research Team)과 문서 작성 팀(Doc Writing Team)을 정의합니다.
1.4.1 연구 팀(Research Team)
연구 팀은 search agent와 web scraping을 담당하는 research_agent라는 두 개의 작업자 노드를 가집니다. 이들을 생성하고 팀 감독자도 설정해 보겠습니다.
import operator
from typing import List, TypedDict
from typing_extensions import Annotated
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_openai.chat_models import ChatOpenAI
from langgraph.prebuilt import create_react_agent
# 상태 정의
class ResearchState(TypedDict):
messages: Annotated[List[BaseMessage], operator.add] # 메시지
team_members: List[str] # 멤버 에이전트 목록
next: str # Supervisor 에이전트에게 다음 작업자를 선택하도록 지시
# LLM 초기화
llm = ChatOpenAI(model=MODEL_NAME, temperature=0)
# 검색 노드 생성
search_agent = create_react_agent(llm, tools=[tavily_tool])
search_node = agent_factory.create_agent_node(search_agent, name="Searcher")
# 웹 스크래핑 노드 생성
web_scraping_agent = create_react_agent(llm, tools=[scrape_webpages])
web_scraping_node = agent_factory.create_agent_node(
web_scraping_agent, name="WebScraper"
)
# Supervisor 에이전트 생성
supervisor_agent = create_team_supervisor(
MODEL_NAME,
"You are a supervisor tasked with managing a conversation between the"
" following workers: Search, WebScraper. Given the following user request,"
" respond with the worker to act next. Each worker will perform a"
" task and respond with their results and status. When finished,"
" respond with FINISH.",
["Searcher", "WebScraper"],
)다음으로 라우팅할 노드를 선택하는 함수를 정의합니다.
1.4.2 Research Team 그래프 생성
from langchain_teddynote.graphs import visualize_graph
from langgraph.graph import StateGraph
from langgraph.checkpoint.memory import MemorySaver
# 그래프 생성
web_research_graph = StateGraph(ResearchState)
# 노드 추가
web_research_graph.add_node("Searcher", search_node)
web_research_graph.add_node("WebScraper", web_scraping_node)
web_research_graph.add_node("Supervisor", supervisor_agent)
# 엣지 추가
web_research_graph.add_edge("Searcher", "Supervisor")
web_research_graph.add_edge("WebScraper", "Supervisor")
# 조건부 엣지 정의: Supervisor 노드의 결정에 따라 다음 노드로 이동
web_research_graph.add_conditional_edges(
"Supervisor",
get_next_node,
{"Searcher": "Searcher", "WebScraper": "WebScraper", "FINISH": END},
)
# 시작 노드 설정
web_research_graph.set_entry_point("Supervisor")
# 그래프 컴파일
web_research_app = web_research_graph.compile(checkpointer=MemorySaver())
# 그래프 시각화
visualize_graph(web_research_app, xray=True)web_research_app 을 실행합니다.
from langchain_core.runnables import RunnableConfig
from langchain_teddynote.messages import random_uuid, invoke_graph
def run_graph(app, message: str, recursive_limit: int = 50):
# config 설정(재귀 최대 횟수, thread_id)
config = RunnableConfig(
recursion_limit=recursive_limit, configurable={"thread_id": random_uuid()}
)
# 질문 입력
inputs = {
"messages": [HumanMessage(content=message)],
}
# 그래프 실행
invoke_graph(app, inputs, config)
return app.get_state(config).values1.4.3 문서 작성 팀(Doc Writing Team)
이번에는 문서 작성 팀을 생성합니다. 이때, 각 agent에게 서로 다른 file-writing 도구에 대한 접근 권한을 부여합니다.
import operator
from typing import List, TypedDict, Annotated
from pathlib import Path
# 임시 디렉토리 생성 및 작업 디렉토리 설정
WORKING_DIRECTORY = Path("./tmp")
WORKING_DIRECTORY.mkdir(exist_ok=True) # tmp 폴더가 없으면 생성
# 상태 정의
class DocWritingState(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
team_members: str
next: str
current_files: str # 현재 작업중인 파일
# 상태 전처리 노드: 각각의 에이전트가 현재 작업 디렉토리의 상태를 더 잘 인식할 수 있도록 함
def preprocess(state):
# 작성된 파일 목록 초기화
written_files = []
try:
# 작업 디렉토리 내의 모든 파일을 검색하여 상대 경로로 변환
written_files = [
f.relative_to(WORKING_DIRECTORY) for f in WORKING_DIRECTORY.rglob("*")
]
except Exception:
pass
# 작성된 파일이 없으면 상태에 "No files written." 추가
if not written_files:
return {**state, "current_files": "No files written."}
# 작성된 파일 목록을 상태에 추가
return {
**state,
"current_files": "\nBelow are files your team has written to the directory:\n"
+ "\n".join([f" - {f}" for f in written_files]),
}
# LLM 초기화
llm = ChatOpenAI(model=MODEL_NAME)
# 문서 작성 에이전트 생성
doc_writer_agent = create_react_agent(
llm,
tools=[write_document, edit_document, read_document],
state_modifier="You are a arxiv researcher. Your mission is to write arxiv style paper on given topic/resources.",
)
context_aware_doc_writer_agent = preprocess | doc_writer_agent
doc_writing_node = agent_factory.create_agent_node(
context_aware_doc_writer_agent, name="DocWriter"
)
# 노트 작성 노드
note_taking_agent = create_react_agent(
llm,
tools=[create_outline, read_document],
state_modifier="You are an expert in creating outlines for research papers. Your mission is to create an outline for a given topic/resources or documents.",
)
context_aware_note_taking_agent = preprocess | note_taking_agent
note_taking_node = agent_factory.create_agent_node(
context_aware_note_taking_agent, name="NoteTaker"
)
# 차트 생성 에이전트 생성
chart_generating_agent = create_react_agent(
llm, tools=[read_document, python_repl_tool]
)
context_aware_chart_generating_agent = preprocess | chart_generating_agent
chart_generating_node = agent_factory.create_agent_node(
context_aware_chart_generating_agent, name="ChartGenerator"
)
# 문서 작성 팀 감독자 생성
doc_writing_supervisor = create_team_supervisor(
MODEL_NAME,
"You are a supervisor tasked with managing a conversation between the"
" following workers: ['DocWriter', 'NoteTaker', 'ChartGenerator']. Given the following user request,"
" respond with the worker to act next. Each worker will perform a"
" task and respond with their results and status. When finished,"
" respond with FINISH.",
["DocWriter", "NoteTaker", "ChartGenerator"],
)1.4.4 Doc Writing Team 그래프 생성
# 그래프 생성
authoring_graph = StateGraph(DocWritingState)
# 노드 정의
authoring_graph.add_node("DocWriter", doc_writing_node)
authoring_graph.add_node("NoteTaker", note_taking_node)
authoring_graph.add_node("ChartGenerator", chart_generating_node)
authoring_graph.add_node("Supervisor", doc_writing_supervisor)
# 엣지 정의
authoring_graph.add_edge("DocWriter", "Supervisor")
authoring_graph.add_edge("NoteTaker", "Supervisor")
authoring_graph.add_edge("ChartGenerator", "Supervisor")
# 조건부 엣지 정의: Supervisor 노드의 결정에 따라 다음 노드로 이동
authoring_graph.add_conditional_edges(
"Supervisor",
get_next_node,
{
"DocWriter": "DocWriter",
"NoteTaker": "NoteTaker",
"ChartGenerator": "ChartGenerator",
"FINISH": END,
},
)
# 시작 노드 설정
authoring_graph.set_entry_point("Supervisor")
# 그래프 컴파일
authoring_app = authoring_graph.compile(checkpointer=MemorySaver())그래프를 시각화 합니다.
from langchain_teddynote.graphs import visualize_graph
# 그래프 시각화
visualize_graph(authoring_app, xray=True)그래프를 실행하고 결과를 확인합니다.
1.5 Super-Graph 생성
이 설계에서는 상향식 계획 정책을 적용하고 있습니다. 이미 두 개의 그래프를 생성했지만, 이들 간의 작업을 어떻게 라우팅할지 결정해야 합니다.
이를 위해 Super Graph를 정의하여 이전 두 그래프를 조정하고, 이 상위 수준 상태가 서로 다른 그래프 간에 어떻게 공유되는지를 정의하는 연결 요소를 추가할 것입니다.
먼저, 총 감독자 노드를 생성합니다.
from langchain_core.messages import BaseMessage
from langchain_openai.chat_models import ChatOpenAI
# 기본 LLM으로 ChatOpenAI 인스턴스 생성
llm = ChatOpenAI(model=MODEL_NAME)
# 팀 감독자 노드 생성
supervisor_node = create_team_supervisor(
MODEL_NAME,
"You are a supervisor tasked with managing a conversation between the"
" following teams: ['ResearchTeam', 'PaperWritingTeam']. Given the following user request,"
" respond with the worker to act next. Each worker will perform a"
" task and respond with their results and status. When finished,"
" respond with FINISH.",
["ResearchTeam", "PaperWritingTeam"],
)다음은 Super-Graph의 상태와 노드를 정의 합니다.
Super-Graph 는 단순하게 Task 를 라우팅 하는 역할이 주를 이룹니다.
from typing import TypedDict, List, Annotated
import operator
# 상태 정의
class State(TypedDict):
messages: Annotated[List[BaseMessage], operator.add]
# 라우팅 결정
next: str
# 마지막 메시지 반환 노드
def get_last_message(state: State) -> str:
last_message = state["messages"][-1]
if isinstance(last_message, str):
return {"messages": [HumanMessage(content=last_message)]}
else:
return {"messages": [last_message.content]}
# 응답 종합 노드
def join_graph(response: dict):
# 마지막 메시지를 추출하여 메시지 목록으로 반환
return {"messages": [response["messages"][-1]]}1.5.1 Super-Graph 정의
이제 2개의 팀을 연결하는 Super-Graph를 정의합니다.
# 그래프 정의
super_graph = StateGraph(State)
# 노드 정의
super_graph.add_node("ResearchTeam", get_last_message | web_research_app | join_graph)
super_graph.add_node("PaperWritingTeam", get_last_message | authoring_app | join_graph)
super_graph.add_node("Supervisor", supervisor_node)
# 엣지 정의
super_graph.add_edge("ResearchTeam", "Supervisor")
super_graph.add_edge("PaperWritingTeam", "Supervisor")
# 조건부 엣지 추가: Supervisor 의 결정에 따라 다음 노드로 이동
super_graph.add_conditional_edges(
"Supervisor",
get_next_node,
{
"PaperWritingTeam": "PaperWritingTeam",
"ResearchTeam": "ResearchTeam",
"FINISH": END,
},
)
# Supervisor 노드를 시작 노드로 설정
super_graph.set_entry_point("Supervisor")
# 그래프 컴파일
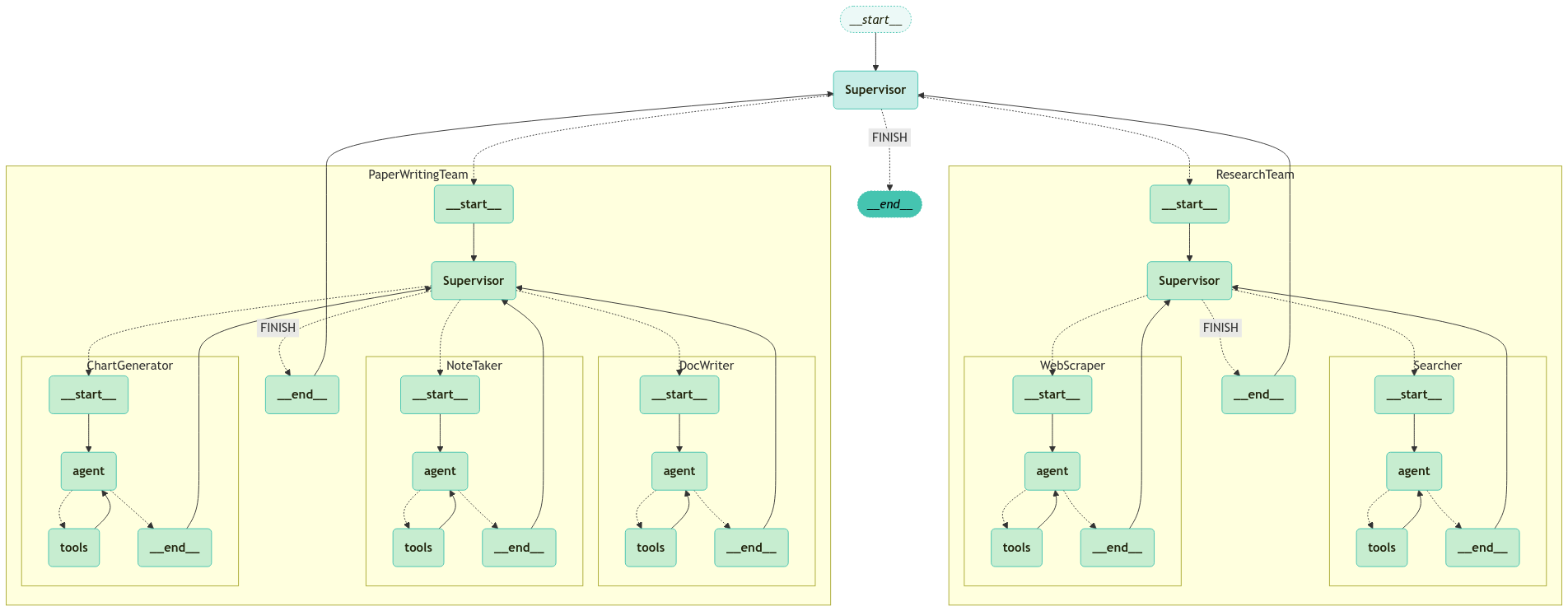
super_graph = super_graph.compile(checkpointer=MemorySaver())그래프를 시각화 합니다.
from langchain_teddynote.graphs import visualize_graph
# 그래프 시각화
visualize_graph(super_graph, xray=True)output = run_graph(
super_graph,
"""주제: multi-agent 구조를 사용하여 복잡한 작업을 수행하는 방법
상세 가이드라인:
- 주제에 대한 Arxiv 논문 형식의 리포트 생성
- Outline 생성
- 각각의 Outline 에 대해서 5문장 이상 작성
- 상세내용 작성시 만약 chart 가 필요하면 차트 생성 및 추가
- 한글로 리포트 작성
- 출처는 APA 형식으로 작성
- 최종 결과는 .md 파일로 저장""",
recursive_limit=150,
)마크다운 형식으로 최종 결과물을 출력합니다.