1 Agentic RAG
에이전트(Agent) 는 검색 도구를 사용할지 여부를 결정해야 할 때 유용합니다. 에이전트와 관련된 내용은 Agent 페이지를 참고하세요.
검색 에이전트를 구현하기 위해서는 LLM에 검색 도구에 대한 접근 권한을 부여하기만 하면 됩니다.
이를 LangGraph에 통합할 수 있습니다.
1.1 환경 설정
1.2 기본 PDF 기반 Retrieval Chain 생성
여기서는 PDF 문서를 기반으로 Retrieval Chain 을 생성합니다. 가장 단순한 구조의 Retrieval Chain 입니다.
단, LangGraph 에서는 Retirever 와 Chain 을 따로 생성합니다. 그래야 각 노드별로 세부 처리를 할 수 있습니다.
참고
- 이전 튜토리얼에서 다룬 내용이므로, 자세한 설명은 생략합니다.
from rag.pdf import PDFRetrievalChain
# PDF 문서를 로드합니다.
pdf = PDFRetrievalChain(["data/SPRI_AI_Brief_2023년12월호_F.pdf"]).create_chain()
# retriever와 chain을 생성합니다.
pdf_retriever = pdf.retriever
pdf_chain = pdf.chain그 다음 retriever_tool 도구를 생성합니다.
참고
document_prompt 는 검색된 문서를 표현하는 프롬프트입니다.
사용가능한 키
page_contentmetadata의 키: (예시)source,page
사용예시
"<document><context>{page_content}</context><metadata><source>{source}</source><page>{page}</page></metadata></document>"
from langchain_core.tools.retriever import create_retriever_tool
from langchain_core.prompts import PromptTemplate
# PDF 문서를 기반으로 검색 도구 생성
retriever_tool = create_retriever_tool(
pdf_retriever,
"pdf_retriever",
"Search and return information about SPRI AI Brief PDF file. It contains useful information on recent AI trends. The document is published on Dec 2023.",
document_prompt=PromptTemplate.from_template(
"<document><context>{page_content}</context><metadata><source>{source}</source><page>{page}</page></metadata></document>"
),
)
# 생성된 검색 도구를 도구 리스트에 추가하여 에이전트에서 사용 가능하도록 설정
tools = [retriever_tool]1.3 Agent 상태
그래프를 정의하겠습니다.
각 노드에 전달되는 state 객체입니다.
상태는 messages 목록으로 구성됩니다.
그래프의 각 노드는 이 목록에 내용을 추가합니다.
from typing import Annotated, Sequence, TypedDict
from langchain_core.messages import BaseMessage
from langgraph.graph.message import add_messages
# 에이전트 상태를 정의하는 타입 딕셔너리, 메시지 시퀀스를 관리하고 추가 동작 정의
class AgentState(TypedDict):
# add_messages reducer 함수를 사용하여 메시지 시퀀스를 관리
messages: Annotated[Sequence[BaseMessage], add_messages]1.4 노드와 엣지
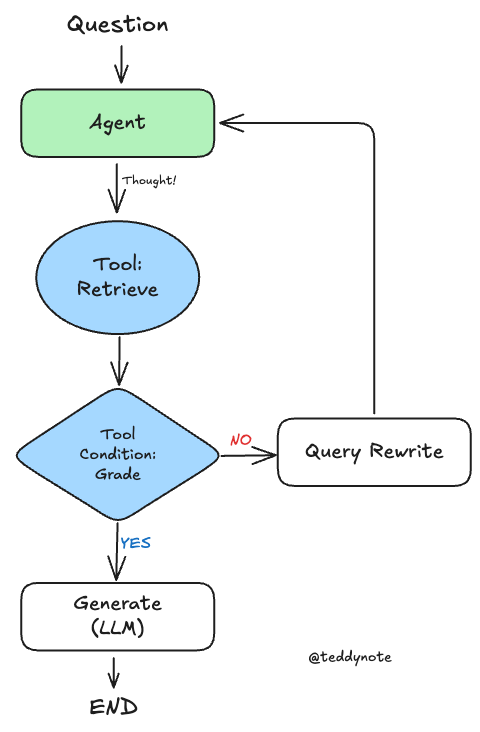
에이전트 기반 RAG 그래프는 다음과 같이 구성될 수 있습니다.
- 상태는 메시지들의 집합입니다
- 각 노드는 상태를 업데이트(추가)합니다
- 조건부 엣지는 다음에 방문할 노드를 결정합니다
간단한 채점기(Grader)를 만들어 보겠습니다.
from typing import Literal
from langchain import hub
from langchain_core.messages import HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import tools_condition
from langchain_teddynote.models import get_model_name, LLMs
# 최신 모델이름 가져오기
MODEL_NAME = get_model_name(LLMs.GPT4)
# 데이터 모델 정의
class grade(BaseModel):
"""A binary score for relevance checks"""
binary_score: str = Field(
description="Response 'yes' if the document is relevant to the question or 'no' if it is not."
)
def grade_documents(state) -> Literal["generate", "rewrite"]:
# LLM 모델 초기화
model = ChatOpenAI(temperature=0, model=MODEL_NAME, streaming=True)
# 구조화된 출력을 위한 LLM 설정
llm_with_tool = model.with_structured_output(grade)
# 프롬프트 템플릿 정의
prompt = PromptTemplate(
template="""You are a grader assessing relevance of a retrieved document to a user question. \n
Here is the retrieved document: \n\n {context} \n\n
Here is the user question: {question} \n
If the document contains keyword(s) or semantic meaning related to the user question, grade it as relevant. \n
Give a binary score 'yes' or 'no' score to indicate whether the document is relevant to the question.""",
input_variables=["context", "question"],
)
# llm + tool 바인딩 체인 생성
chain = prompt | llm_with_tool
# 현재 상태에서 메시지 추출
messages = state["messages"]
# 가장 마지막 메시지 추출
last_message = messages[-1]
# 원래 질문 추출
question = messages[0].content
# 검색된 문서 추출
retrieved_docs = last_message.content
# 관련성 평가 실행
scored_result = chain.invoke({"question": question, "context": retrieved_docs})
# 관련성 여부 추출
score = scored_result.binary_score
# 관련성 여부에 따른 결정
if score == "yes":
print("==== [DECISION: DOCS RELEVANT] ====")
return "generate"
else:
print("==== [DECISION: DOCS NOT RELEVANT] ====")
print(score)
return "rewrite"
def agent(state):
# 현재 상태에서 메시지 추출
messages = state["messages"]
# LLM 모델 초기화
model = ChatOpenAI(temperature=0, streaming=True, model=MODEL_NAME)
# retriever tool 바인딩
model = model.bind_tools(tools)
# 에이전트 응답 생성
response = model.invoke(messages)
# 기존 리스트에 추가되므로 리스트 형태로 반환
return {"messages": [response]}
def rewrite(state):
print("==== [QUERY REWRITE] ====")
# 현재 상태에서 메시지 추출
messages = state["messages"]
# 원래 질문 추출
question = messages[0].content
# 질문 개선을 위한 프롬프트 구성
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# LLM 모델로 질문 개선
model = ChatOpenAI(temperature=0, model=MODEL_NAME, streaming=True)
# Query-Transform 체인 실행
response = model.invoke(msg)
# 재작성된 질문 반환
return {"messages": [response]}
def generate(state):
# 현재 상태에서 메시지 추출
messages = state["messages"]
# 원래 질문 추출
question = messages[0].content
# 가장 마지막 메시지 추출
docs = messages[-1].content
# RAG 프롬프트 템플릿 가져오기
prompt = hub.pull("teddynote/rag-prompt")
# LLM 모델 초기화
llm = ChatOpenAI(model_name=MODEL_NAME, temperature=0, streaming=True)
# RAG 체인 구성
rag_chain = prompt | llm | StrOutputParser()
# 답변 생성 실행
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}1.5 그래프
call_model에이전트로 시작합니다- 에이전트가 함수를 호출할지 결정합니다
- 함수 호출을 결정한 경우, 도구(retriever)를 호출하기 위한
action을 실행합니다 - 도구의 출력값을 메시지(
state)에 추가하여 에이전트를 호출합니다
from langgraph.graph import END, StateGraph, START
from langgraph.prebuilt import ToolNode
from langgraph.checkpoint.memory import MemorySaver
# AgentState 기반 상태 그래프 워크플로우 초기화
workflow = StateGraph(AgentState)
# 노드 정의
workflow.add_node("agent", agent) # 에이전트 노드
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # 검색 노드
workflow.add_node("rewrite", rewrite) # 질문 재작성 노드
workflow.add_node("generate", generate) # 관련 문서 확인 후 응답 생성 노드
# 엣지 연결
workflow.add_edge(START, "agent")
# 검색 여부 결정을 위한 조건부 엣지 추가
workflow.add_conditional_edges(
"agent",
# 에이전트 결정 평가
tools_condition,
{
# 조건 출력을 그래프 노드에 매핑
"tools": "retrieve",
END: END,
},
)
# 액션 노드 실행 후 처리될 엣지 정의
workflow.add_conditional_edges(
"retrieve",
# 문서 품질 평가
grade_documents,
)
workflow.add_edge("generate", END)
workflow.add_edge("rewrite", "agent")
# 그래프 컴파일
graph = workflow.compile(checkpointer=MemorySaver())그래프를 시각화합니다.
1.6 그래프 실행
from langchain_core.runnables import RunnableConfig
from langchain_teddynote.messages import stream_graph, invoke_graph, random_uuid
# config 설정(재귀 최대 횟수, thread_id)
config = RunnableConfig(recursion_limit=10, configurable={"thread_id": random_uuid()})
# 사용자의 에이전트 메모리 유형에 대한 질문을 포함하는 입력 데이터 구조 정의
inputs = {
"messages": [
("user", "삼성전자가 개발한 생성형 AI 의 이름은?"),
]
}
# 그래프 실행
invoke_graph(graph, inputs, config)아래는 문서 검색이 불필요한 질문의 예시입니다.
# 문서 검색이 불가능한 질문 예시
inputs = {
"messages": [
("user", "대한민국의 수도는?"),
]
}
# 그래프 실행
stream_graph(graph, inputs, config, ["agent", "rewrite", "generate"])아래는 임의로 문서 검색이 불가능한 질문 예시입니다.
따라서, 문서를 지속적으로 검색하는 과정에서 GraphRecursionError 가 발생하였습니다.
from langgraph.errors import GraphRecursionError
# 문서 검색이 불가능한 질문 예시
inputs = {
"messages": [
("user", "테디노트의 랭체인 튜토리얼에 대해서 알려줘"),
]
}
try:
# 그래프 실행
stream_graph(graph, inputs, config, ["agent", "rewrite", "generate"])
except GraphRecursionError as recursion_error:
print(f"GraphRecursionError: {recursion_error}")다음 튜토리얼에서는 이를 해결하는 방법을 다룹니다.