이번 튜토리얼에서는 웹 검색(Web Search), PDF 문서 기반 검색(RAG), 이미지 생성(Image Generation) 등을 통해 보고서를 작성하는 에이전트를 만들어 보겠습니다.
참고
DallEAPIWrapper 에 대한 임시 버그 안내사항 (작성일: 2024-10-13)
- 현재 langchain 0.3.x 이상 버전에서
DallEAPIWrapper에 대한 임시 버그가 있습니다. (401 오류: invalid API key)
따라서, 아래의 코드를 오류 없이 실행하기 위해서는 LangChain 버전을 0.2.16 으로 변경해야 합니다.
아래의 주석을 해제하고 실행하면 LangChain 버전을 0.2.16 으로 변경됩니다.
하지만, 이후 내용에서는 LangChain 버전을 0.3.x 이상으로 변경하여 사용하기 때문에
poetry shell 명령어를 통해 다시 최신 langchain 버전으로 변경해야 합니다.
이 과정이 번거로운 분들은 일단 DallEAPIWrapper 를 사용하지 않고 진행하셔도 무방합니다.
업그레이드/다운그레이드 후에는 반드시 상단 메뉴의 “Restart” 버튼을 클릭한 뒤 진행해야 합니다.
# 임시 버전 다운그레이드 명령어 (실행 후 restart)
# !pip install langchain==0.2.16 langchain-community==0.2.16 langchain-text-splitters==0.2.4 langchain-experimental==0.0.65 langchain-openai==0.1.20# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install -qU langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("CH15-Agent-Projects")1 도구 정의
1.1 웹 검색도구: Tavily Search
LangChain에는 Tavily 검색 엔진을 도구로 쉽게 사용할 수 있는 내장 도구가 있습니다.
Tavily Search 를 사용하기 위해서는 API KEY를 발급 받아야 합니다.
발급 받은 API KEY 를 다음과 같이 환경변수에 등록 합니다.
.env 파일에 다음과 같이 등록합니다.
TAVILY_API_KEY=발급 받은 Tavily API KEY 입력
1.2 문서 기반 문서 검색 도구: Retriever
우리의 데이터에 대해 조회를 수행할 retriever도 생성합니다.
실습에 활용한 문서
소프트웨어정책연구소(SPRi) - 2023년 12월호
- 저자: 유재흥(AI정책연구실 책임연구원), 이지수(AI정책연구실 위촉연구원)
- 링크: https://spri.kr/posts/view/23669
- 파일명:
SPRI_AI_Brief_2023년12월호_F.pdf
실습을 위해 다운로드 받은 파일을 data 폴더로 복사해 주시기 바랍니다
다음은 retriever 를 생성하고, 생성한 retriever 를 기반으로 도구를 생성합니다.
먼저, 문서를 로드하고, 분할한 뒤 retriever 를 생성합니다.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain.document_loaders import PyMuPDFLoader
# PDF 파일 로드. 파일의 경로 입력
loader = PyMuPDFLoader("data/SPRI_AI_Brief_2023년12월호_F.pdf")
# 텍스트 분할기를 사용하여 문서를 분할합니다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
# 문서를 로드하고 분할합니다.
split_docs = loader.load_and_split(text_splitter)
# VectorStore를 생성합니다.
vector = FAISS.from_documents(split_docs, OpenAIEmbeddings())
# Retriever를 생성합니다.
retriever = vector.as_retriever()다음은 retriever 를 도구로 정의합니다.
이때, document_prompt 는 문서의 내용을 표시하는 템플릿을 정의합니다.
참고
기본 값은 문서의
page_content만 표기합니다.따라서, 나중에 문서의 페이지 번호나 출처등을 표시하기 위해서는 템플릿을 따로 정의해야 합니다.
from langchain.tools.retriever import create_retriever_tool
from langchain_core.prompts import PromptTemplate
# 문서의 내용을 표시하는 템플릿을 정의합니다.
document_prompt = PromptTemplate.from_template(
"<document><content>{page_content}</content><page>{page}</page><filename>{source}</filename></document>"
)
# retriever 를 도구로 정의합니다.
retriever_tool = create_retriever_tool(
retriever,
name="pdf_search",
description="use this tool to search for information in the PDF file",
document_prompt=document_prompt,
)1.3 DallE 이미지 생성 도구
이번에는 Dall-E 이미지 생성 도구를 생성합니다.
주요 속성
model: 사용할 DALL-E 모델 이름 (기본값: “dall-e-2”, “dall-e-3”)n: 생성할 이미지 수 (기본값: 1)size: 생성할 이미지 크기- “dall-e-2”: “1024x1024”, “512x512”, “256x256”
- “dall-e-3”: “1024x1024”, “1792x1024”, “1024x1792”
style: 생성될 이미지의 스타일 (기본값: “natural”, “vivid”)quality: 생성될 이미지의 품질 (기본값: “standard”, “hd”)max_retries: 생성 시 최대 재시도 횟수
from langchain_community.utilities.dalle_image_generator import DallEAPIWrapper
from langchain.tools import tool
# DallE API Wrapper를 생성합니다.
dalle = DallEAPIWrapper(model="dall-e-3", size="1024x1024", quality="standard", n=1)
# DallE API Wrapper를 도구로 정의합니다.
@tool
def dalle_tool(query):
"""use this tool to generate image from text"""
return dalle.run(query)1.4 파일 관리 도구
파일 관리 도구들
CopyFileTool: 파일 복사DeleteFileTool: 파일 삭제FileSearchTool: 파일 검색MoveFileTool: 파일 이동ReadFileTool: 파일 읽기WriteFileTool: 파일 쓰기ListDirectoryTool: 디렉토리 목록 조회
from langchain_community.agent_toolkits import FileManagementToolkit
# 작업 디렉토리 경로 설정
working_directory = "tmp"
# 파일 관리 도구 생성(파일 쓰기, 읽기, 디렉토리 목록 조회)
file_tools = FileManagementToolkit(
root_dir=str(working_directory),
selected_tools=["write_file", "read_file", "list_directory"],
).get_tools()
# 생성된 파일 관리 도구 출력
file_tools자, 이제 모든 도구를 종합합니다.
2 Agent 생성
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_openai import ChatOpenAI
from langchain_teddynote.messages import AgentStreamParser
# session_id 를 저장할 딕셔너리 생성
store = {}
# 프롬프트 생성
# 프롬프트는 에이전트에게 모델이 수행할 작업을 설명하는 텍스트를 제공합니다. (도구의 이름과 역할을 입력)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are a helpful assistant. "
"You are a professional researcher. "
"You can use the pdf_search tool to search for information in the PDF file. "
"You can find further information by using search tool. "
"You can use image generation tool to generate image from text. "
"Finally, you can use file management tool to save your research result into files.",
),
("placeholder", "{chat_history}"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
]
)
# LLM 생성
llm = ChatOpenAI(model="gpt-4o-mini")
# Agent 생성
agent = create_tool_calling_agent(llm, tools, prompt)
# AgentExecutor 생성
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=False,
handle_parsing_errors=True,
)
# session_id 를 기반으로 세션 기록을 가져오는 함수
def get_session_history(session_ids):
if session_ids not in store: # session_id 가 store에 없는 경우
# 새로운 ChatMessageHistory 객체를 생성하여 store에 저장
store[session_ids] = ChatMessageHistory()
return store[session_ids] # 해당 세션 ID에 대한 세션 기록 반환
# 채팅 메시지 기록이 추가된 에이전트를 생성합니다.
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
# 대화 session_id
get_session_history,
# 프롬프트의 질문이 입력되는 key: "input"
input_messages_key="input",
# 프롬프트의 메시지가 입력되는 key: "chat_history"
history_messages_key="chat_history",
)
# 스트림 파서 생성
agent_stream_parser = AgentStreamParser()자, 이제 에이전트를 실행해 봅시다.
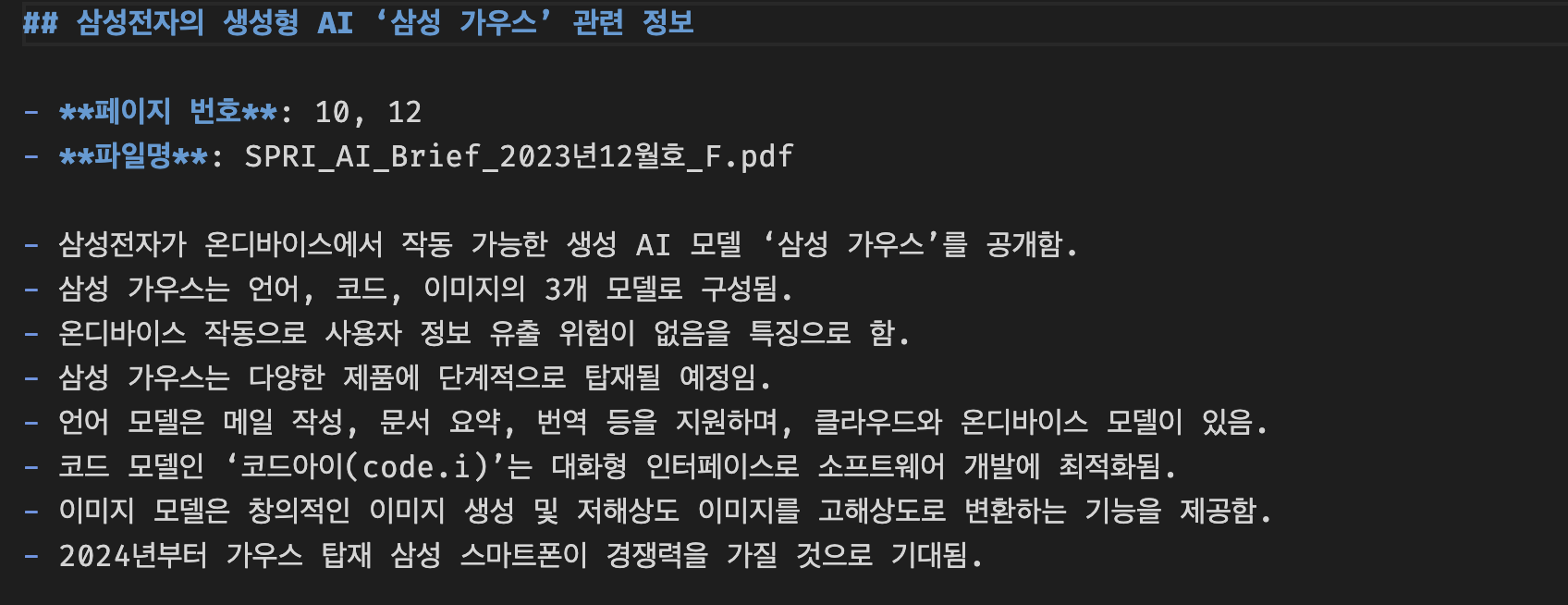
# 에이전트 실행
result = agent_with_chat_history.stream(
{
"input": "삼성전자가 개발한 `생성형 AI` 와 관련된 유용한 정보들을 PDF 문서에서 찾아서 bullet point로 정리해 주세요. "
"한글로 작성해주세요."
"다음으로는 `report.md` 파일을 새롭게 생성하여 정리한 내용을 저장해주세요. \n\n"
"#작성방법: \n"
"1. markdown header 2 크기로 적절한 제목을 작성하세요. \n"
"2. 발췌한 PDF 문서의 페이지 번호, 파일명을 기입하세요(예시: page 10, filename.pdf). \n"
"3. 정리된 bullet point를 작성하세요. \n"
"4. 작성이 완료되면 파일을 `report.md` 에 저장하세요. \n"
"5. 마지막으로 저장한 `report.md` 파일을 읽어서 출력해 주세요. \n"
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)생성된 보고서 파일(report.md)의 내용을 확인하면 다음과 같이 출력됩니다.
다음으로는 웹 검색을 통해 보고서 파일을 업데이트 해 봅시다.
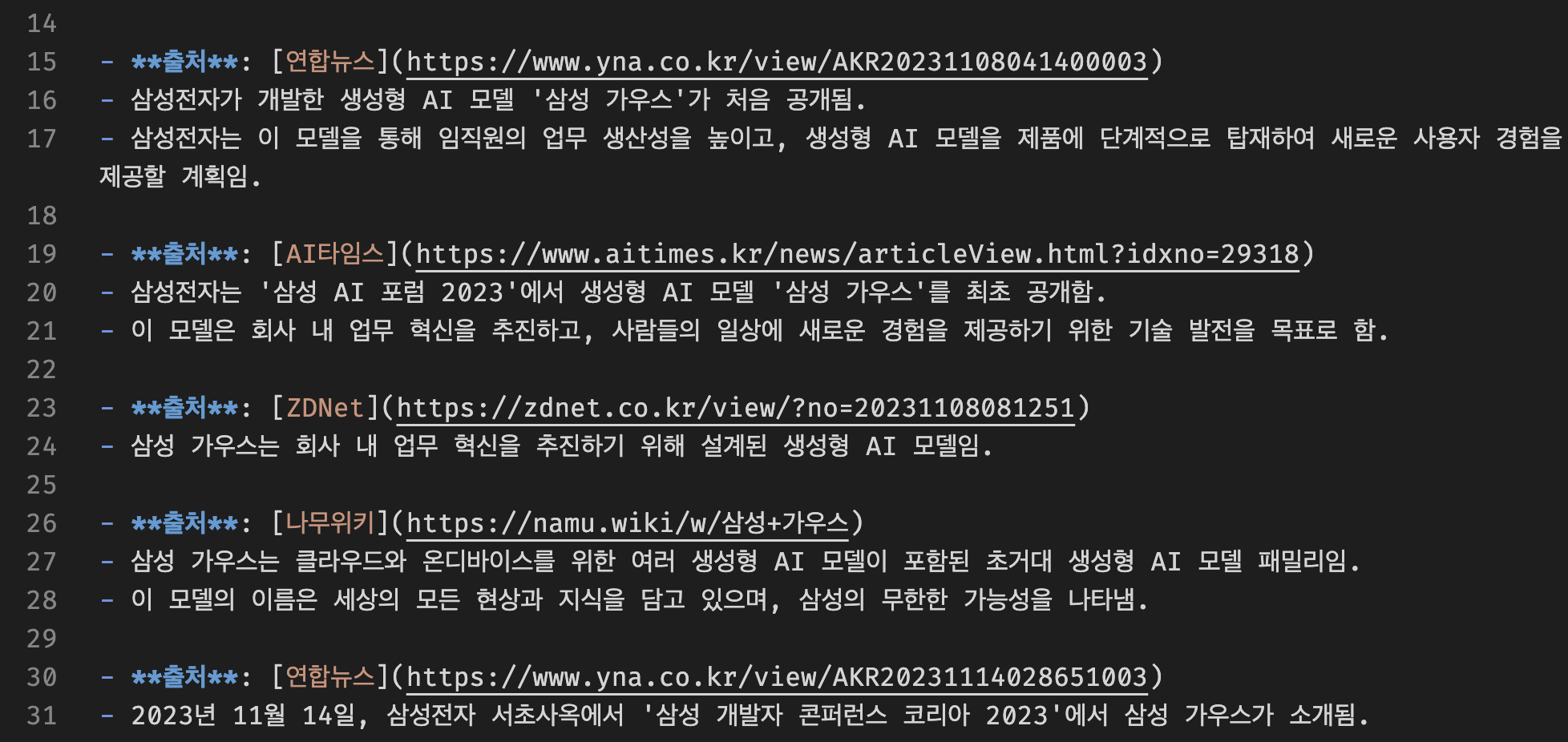
# 웹 검색을 통해 보고서 파일 업데이트
result = agent_with_chat_history.stream(
{
"input": "이번에는 삼성전자가 개발한 `생성형 AI` 와 관련된 정보들을 웹 검색하고, 검색한 결과를 정리해 주세요. "
"한글로 작성해주세요."
"다음으로는 `report.md` 파일을 열어서 기존의 내용을 읽고, 웹 검색하여 찾은 정보를 이전에 작성한 형식에 맞춰 뒷 부분에 추가해 주세요. \n\n"
"#작성방법: \n"
"1. markdown header 2 크기로 적절한 제목을 작성하세요. \n"
"2. 정보의 출처(url)를 기입하세요(예시: 출처: 네이버 지식백과). \n"
"3. 정리된 웹검색 내용을 작성하세요. \n"
"4. 작성이 완료되면 파일을 `report.md` 에 저장하세요. \n"
"5. 마지막으로 저장한 `report.md` 파일을 읽어서 출력해 주세요. \n"
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)업데이트된 보고서 파일(report.md)의 내용을 확인하면 다음과 같이 출력됩니다.
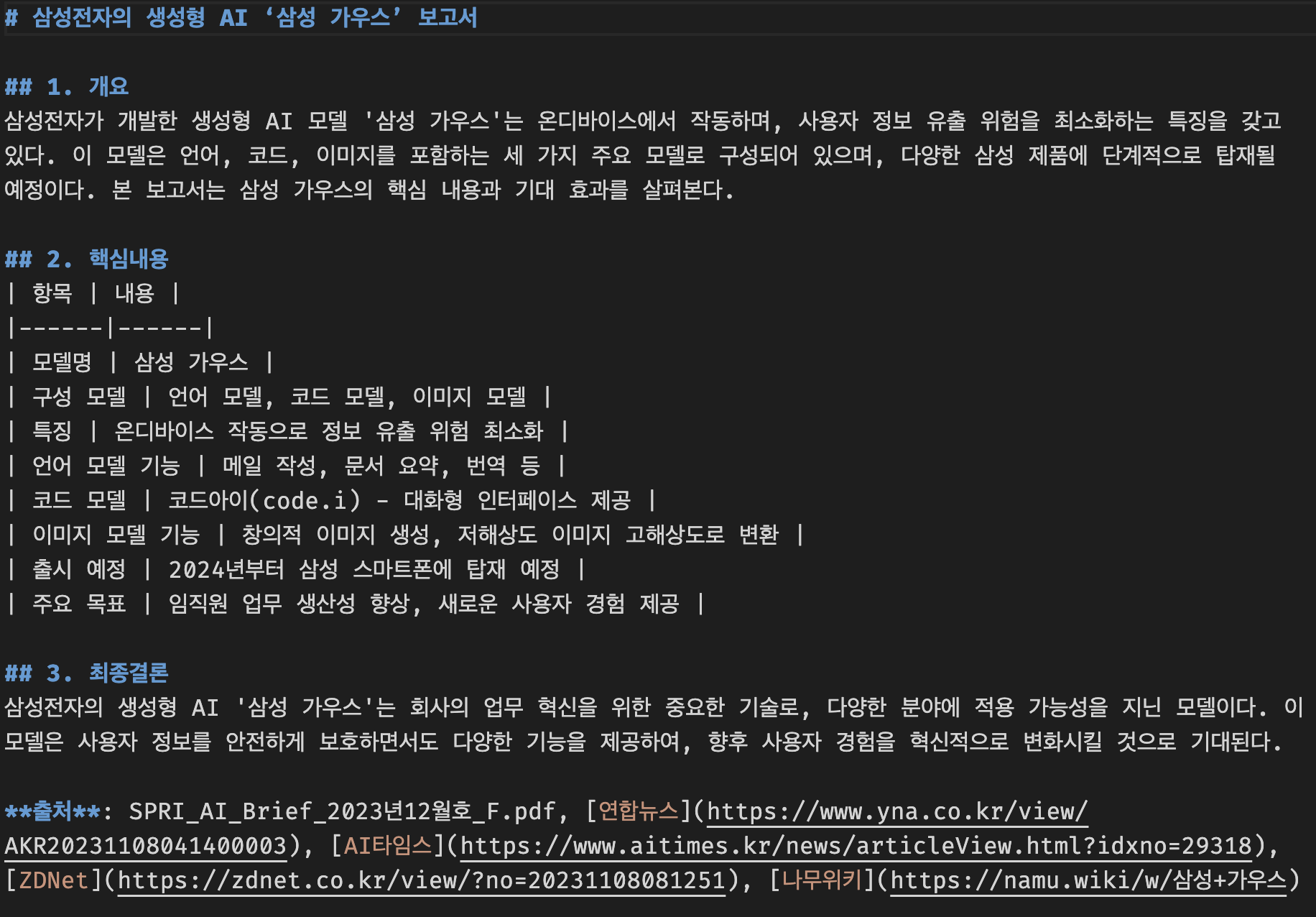
# 보고서 작성을 요청합니다.
result = agent_with_chat_history.stream(
{
"input": "`report.md` 파일을 열어서 안의 내용을 출력하세요. "
"출력된 내용을 바탕으로, 전문적인 수준의 보고서를 작성하세요. "
"보고서는 총 3개의 섹션으로 구성되어야 합니다:\n"
"1. 개요: 보고서 abstract 를 300자 내외로 작성하세요.\n"
"2. 핵심내용: 보고서의 핵심 내용을 작성하세요. 정리된 표를 markdown 형식으로 작성하여 추가하세요. "
"3. 최종결론: 보고서의 최종 결론을 작성하세요. 출처(파일명, url 등)을 표시하세요."
"마지막으로 작성된 결과물을 `report-2.md` 파일에 저장하세요."
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)새롭게 작성된 보고서 파일(report-2.md)의 내용을 확인하면 다음과 같이 출력됩니다.
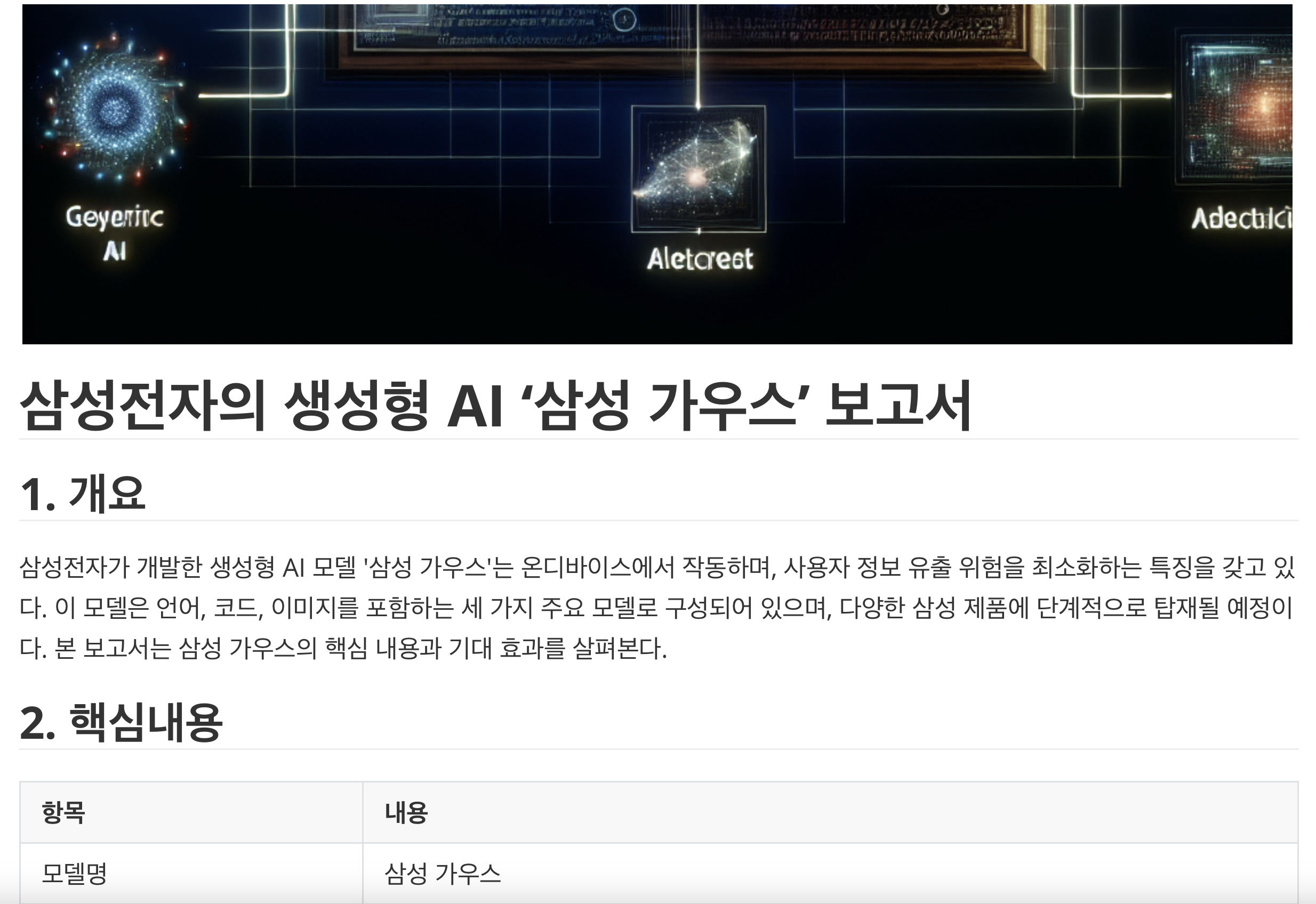
마지막으로, 보고서 내용을 기반으로 이미지 생성을 요청해 봅시다.
# 이미지 생성을 요청합니다.
result = agent_with_chat_history.stream(
{
"input": "`report-2.md` 파일을 열어서 안의 내용을 출력하세요. "
"출력된 내용에 어울리는 이미지를 생성하세요. "
"생성한 이미지의 url 을 markdown 형식으로 보고서의 가장 상단에 추가하세요. "
"마지막으로 작성된 결과물을 `report-3.md` 파일에 저장하세요."
},
config={"configurable": {"session_id": "abc123"}},
)
print("Agent 실행 결과:")
for step in result:
agent_stream_parser.process_agent_steps(step)마지막으로 생성된 보고서 파일(report-3.md)의 내용을 일부를 확인하면 다음과 같이 출력됩니다.