1 1. 사전작업(Pre-processing) - 1~4 단계

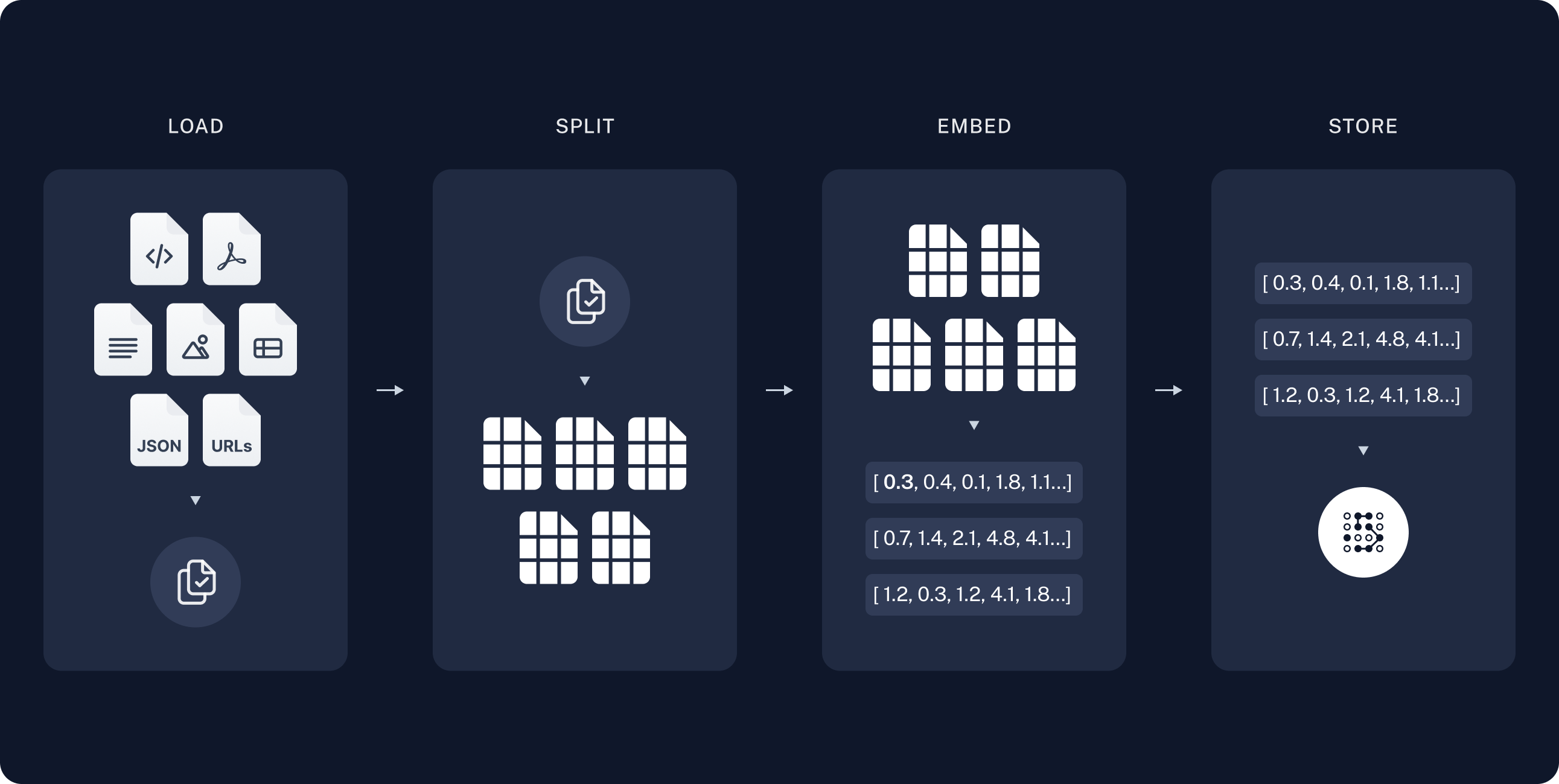
사전 작업 단계에서는 데이터 소스를 Vector DB (저장소) 에 문서를 로드-분할-임베딩-저장 하는 4단계를 진행합니다.
- 1단계 문서로드(Document Load): 문서 내용을 불러옵니다.
- 2단계 분할(Text Split): 문서를 특정 기준(Chunk) 으로 분할합니다.
- 3단계 임베딩(Embedding): 분할된(Chunk) 를 임베딩하여 저장합니다.
- 4단계 벡터DB 저장: 임베딩된 Chunk 를 DB에 저장합니다.
2 2. RAG 수행(RunTime) - 5~8 단계

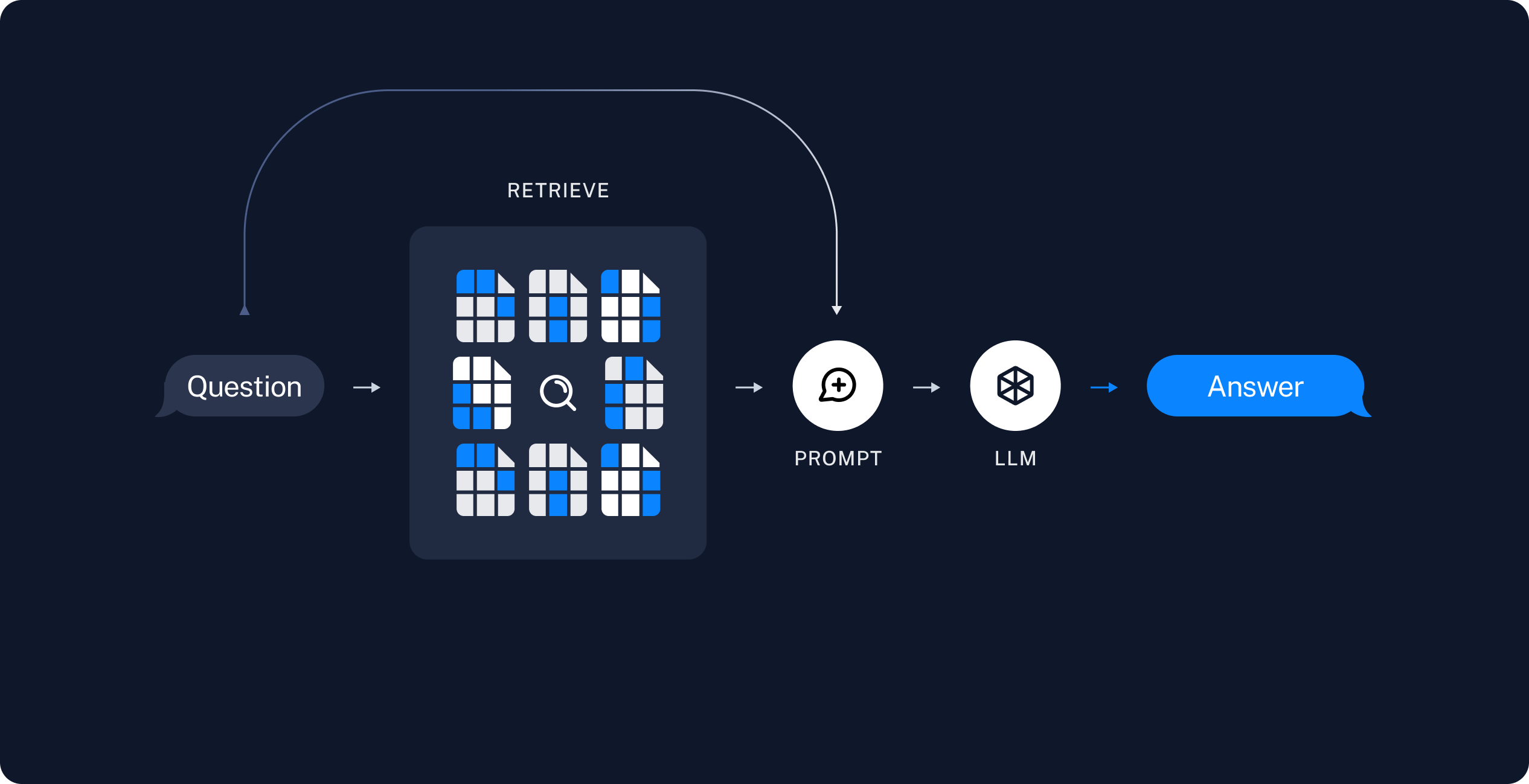
- 5단계 검색기(Retriever): 쿼리(Query) 를 바탕으로 DB에서 검색하여 결과를 가져오기 위하여 리트리버를 정의합니다. 리트리버는 검색 알고리즘이며(Dense, Sparse) 리트리버로 나뉘게 됩니다.
- Dense: 유사도 기반 검색(FAISS, DPR)
- Sparse: 키워드 기반 검색(BM25, TF-IDF)
- 6단계 프롬프트: RAG 를 수행하기 위한 프롬프트를 생성합니다. 프롬프트의 context 에는 문서에서 검색된 내용이 입력됩니다. 프롬프트 엔지니어링을 통하여 답변의 형식을 지정할 수 있습니다.
- 7단계 LLM: 모델을 정의합니다.(GPT-3.5, GPT-4, Claude, etc..)
- 8단계 Chain: 프롬프트 - LLM - 출력 에 이르는 체인을 생성합니다.
3 환경설정
API KEY 를 설정합니다.
LangChain으로 구축한 애플리케이션은 여러 단계에 걸쳐 LLM 호출을 여러 번 사용하게 됩니다. 이러한 애플리케이션이 점점 더 복잡해짐에 따라, 체인이나 에이전트 내부에서 정확히 무슨 일이 일어나고 있는지 조사할 수 있는 능력이 매우 중요해집니다. 이를 위한 최선의 방법은 LangSmith를 사용하는 것입니다.
LangSmith가 필수는 아니지만, 유용합니다. LangSmith를 사용하고 싶다면, 위의 링크에서 가입한 후, 로깅 추적을 시작하기 위해 환경 변수를 설정해야 합니다.
4 네이버 뉴스 기반 QA(Question-Answering) 챗봇
이번 튜토리얼에는 네이버 뉴스기사의 내용에 대해 질문할 수 있는 뉴스기사 QA 앱 을 구축할 것입니다.
이 가이드에서는 OpenAI 챗 모델과 임베딩, 그리고 Chroma 벡터 스토어를 사용할 것입니다.
먼저 다음의 과정을 통해 간단한 인덱싱 파이프라인과 RAG 체인을 약 20줄의 코드로 구현할 수 있습니다.
라이브러리
bs4는 웹 페이지를 파싱하기 위한 라이브러리입니다.langchain은 AI와 관련된 다양한 기능을 제공하는 라이브러리로, 여기서는 특히 텍스트 분할(RecursiveCharacterTextSplitter), 문서 로딩(WebBaseLoader), 벡터 저장(Chroma,FAISS), 출력 파싱(StrOutputParser), 실행 가능한 패스스루(RunnablePassthrough) 등을 다룹니다.langchain_openai모듈을 통해 OpenAI의 챗봇(ChatOpenAI)과 임베딩(OpenAIEmbeddings) 기능을 사용할 수 있습니다.
import bs4
from langchain import hub
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings웹 페이지의 내용을 로드하고, 텍스트를 청크로 나누어 인덱싱하는 과정을 거친 후, 관련된 텍스트 스니펫을 검색하여 새로운 내용을 생성하는 과정을 구현합니다.
WebBaseLoader는 지정된 웹 페이지에서 필요한 부분만을 파싱하기 위해 bs4.SoupStrainer를 사용합니다.
[참고]
bs4.SoupStrainer는 편리하게 웹에서 원하는 요소를 가져올 수 있도록 해줍니다.
(예시)
bs4.SoupStrainer(
"div",
attrs={"class": ["newsct_article _article_body", "media_end_head_title"]},
)# 뉴스기사 내용을 로드하고, 청크로 나누고, 인덱싱합니다.
loader = WebBaseLoader(
web_paths=("https://n.news.naver.com/article/437/0000378416",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
"div",
attrs={"class": ["newsct_article _article_body", "media_end_head_title"]},
)
),
)
docs = loader.load()
print(f"문서의 수: {len(docs)}")
docsRecursiveCharacterTextSplitter는 문서를 지정된 크기의 청크로 나눕니다.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
splits = text_splitter.split_documents(docs)
len(splits)FAISS 혹은 Chroma와 같은 vectorstore는 이러한 청크를 바탕으로 문서의 벡터 표현을 생성합니다.
# 벡터스토어를 생성합니다.
vectorstore = FAISS.from_documents(documents=splits, embedding=OpenAIEmbeddings())
# 뉴스에 포함되어 있는 정보를 검색하고 생성합니다.
retriever = vectorstore.as_retriever()vectorstore.as_retriever()를 통해 생성된 검색기는 hub.pull로 가져온 프롬프트와 ChatOpenAI 모델을 사용하여 새로운 내용을 생성합니다.
마지막으로, StrOutputParser는 생성된 결과를 문자열로 파싱합니다.
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template(
"""당신은 질문-답변(Question-Answering)을 수행하는 친절한 AI 어시스턴트입니다. 당신의 임무는 주어진 문맥(context) 에서 주어진 질문(question) 에 답하는 것입니다.
검색된 다음 문맥(context) 을 사용하여 질문(question) 에 답하세요. 만약, 주어진 문맥(context) 에서 답을 찾을 수 없다면, 답을 모른다면 `주어진 정보에서 질문에 대한 정보를 찾을 수 없습니다` 라고 답하세요.
한글로 답변해 주세요. 단, 기술적인 용어나 이름은 번역하지 않고 그대로 사용해 주세요.
#Question:
{question}
#Context:
{context}
#Answer:"""
)hub 에서 teddynote/rag-prompt-korean 프롬프트를 다운로드 받아 입력할 수 있습니다. 이런 경우 별도의 프롬프트 작성과정이 생략됩니다.
llm = ChatOpenAI(model_name="gpt-4.1-mini", temperature=0)
# 체인을 생성합니다.
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)스트리밍 출력을 위하여 stream_response 를 사용합니다.