1 문제 상황: 무관한 문서의 과다 검색
RAG 시스템에서 리트리버가 과도한 수의 문서를 반환하면 할루시네이션 가능성이 증가한다. 예를 들어, 실제 질의와 관련된 부분이 5곳(k=5)에만 있는데 k=20으로 설정하면, LLM이 15곳의 무관한 내용까지 검토하게 되어 마치 함정을 설치하는 것과 같다. 이상적으로는 LLM에게 정확히 5곳만 제공해야 하지만, 질의를 미리 알 수 없으므로 이를 구현하기는 어렵다.
2 해결책: 문맥 압축 (Contextual Compression)
ContextualCompressionRetriever는 이 문제를 해결하기 위해 설계되었다. 다량의 문서(k=10~20)를 검색한 후 문맥 압축을 통해 관련성 높은 문서만 선별(k=5)하여 반환한다.
압축 방식의 종류:
- LLM 기반 압축: LLM을 활용하여 관련 내용만 추출
- 장점: 할루시네이션 감소, 의미 기반 판단
- 단점: 비용 증가, 응답 시간 증가
- Embedding 기반 압축: 유사도 임계값으로 문서 필터링
- 장점: 저비용, 빠른 처리, 중복 제거 가능
- 단점: 의미적 이해 제한
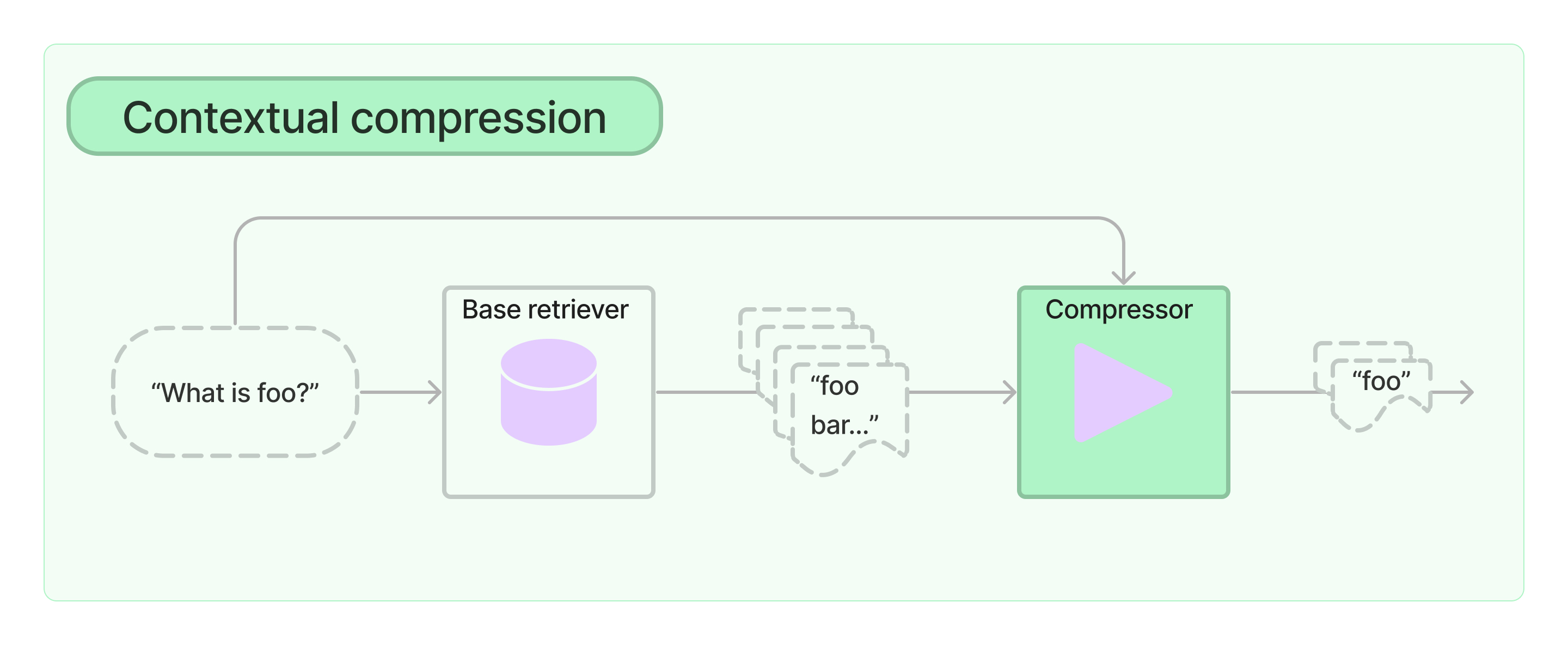
3 작동 원리
ContextualCompressionRetriever는 두 단계로 작동한다:
- 검색 단계: 질의를 base retriever에 전달하여 초기 문서 검색 (비효율적이지만 폭넓은 범위)
- 압축 단계: Document Compressor를 통해 관련성 낮은 문서 제거 또는 내용 축약
“압축”의 의미: - 개별 문서의 내용을 축약 (관련 내용만 추출) - 무관한 문서를 완전히 필터링 제거
이를 통해 LLM에 전달되는 토큰 수를 줄이면서도 관련성을 유지한다.
출처: https://drive.google.com/uc?id=1CtNgWODXZudxAWSRiWgSGEoTNrUFT98v
4 환경 설정
5 헬퍼 함수: 문서 출력
6 기본 Retriever 설정
벡터 스토어 retriever를 초기화하고 문서를 검색합니다. 기본 retriever는 관련 문서와 무관한 문서를 함께 반환합니다.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
# 문서 로드 및 청크 분할
loader = TextLoader("./data/appendix-keywords.txt")
text_splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
texts = loader.load_and_split(text_splitter)
# 벡터 저장소 생성 및 검색기 설정
retriever = FAISS.from_documents(texts, OpenAIEmbeddings()).as_retriever()
# 검색 실행
docs = retriever.invoke("Semantic Search 에 대해서 알려줘.")
pretty_print_docs(docs)문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.
연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝
Embedding
----------------------------------------------------------------------------------------------------
문서 2:
정의: 키워드 검색은 사용자가 입력한 키워드를 기반으로 정보를 찾는 과정입니다. 이는 대부분의 검색 엔진과 데이터베이스 시스템에서 기본적인 검색 방식으로 사용됩니다.
예시: 사용자가 "커피숍 서울"이라고 검색하면, 관련된 커피숍 목록을 반환합니다.
연관키워드: 검색 엔진, 데이터 검색, 정보 검색
Page Rank
----------------------------------------------------------------------------------------------------
문서 3:
정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.
예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.
연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진
Word2Vec
----------------------------------------------------------------------------------------------------
문서 4:
정의: 페이지 랭크는 웹 페이지의 중요도를 평가하는 알고리즘으로, 주로 검색 엔진 결과의 순위를 결정하는 데 사용됩니다. 이는 웹 페이지 간의 링크 구조를 분석하여 평가합니다.
예시: 구글 검색 엔진은 페이지 랭크 알고리즘을 사용하여 검색 결과의 순위를 정합니다.
연관키워드: 검색 엔진 최적화, 웹 분석, 링크 분석
데이터 마이닝결과 해석: 기본 리트리버는 쿼리와 무관한 문서(2, 3, 4번)까지 함께 반환됨. 이로 인해 LLM에 불필요한 컨텍스트가 전달되어 비용과 할루시네이션 위험 증가.
7 맥락적 압축(ContextualCompression)
LLMChainExtractor는 LLM을 사용하여 문서에서 관련 내용만 추출합니다.
from langchain_teddynote.document_compressors import LLMChainExtractor # deprecated lang chain module을 테디가 다시 커스터마이징함
from langchain.retrievers import ContextualCompressionRetriever
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-4o-mini")
# LLM을 사용하여 문서 압축기 생성
compressor = LLMChainExtractor.from_llm(llm)
# compressor = LLMChainExtractor.from_llm(llm, prompt= PromptTemplate.from_template("""주어진 문서에서 entity 들을 추출해 주세요.""")) # 이건 원본 문서를 paraphrasing하는 역할을 한다.
compression_retriever = ContextualCompressionRetriever(
# 문서 압축기와 리트리버를 사용하여 컨텍스트 압축 리트리버 생성
base_compressor=compressor,
base_retriever=retriever,
)
# 일반 리트리버 vs 압축 리트리버 성능 비교
## 일반 리트리버
pretty_print_docs(retriever.invoke("Semantic Search 에 대해서 알려줘."))
print("=========================================================")
print("============== LLMChainExtractor 적용 후 ==================")
## 압축 리트리버
compressed_docs = (
compression_retriever.invoke( # 컨텍스트 압축 리트리버를 사용하여 관련 문서 검색
"Semantic Search 에 대해서 알려줘."
)
)
pretty_print_docs(compressed_docs) # 검색된 문서를 예쁘게 출력문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.
연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝
Embedding
----------------------------------------------------------------------------------------------------
문서 2:
정의: 키워드 검색은 사용자가 입력한 키워드를 기반으로 정보를 찾는 과정입니다. 이는 대부분의 검색 엔진과 데이터베이스 시스템에서 기본적인 검색 방식으로 사용됩니다.
예시: 사용자가 "커피숍 서울"이라고 검색하면, 관련된 커피숍 목록을 반환합니다.
연관키워드: 검색 엔진, 데이터 검색, 정보 검색
Page Rank
----------------------------------------------------------------------------------------------------
문서 3:
정의: 크롤링은 자동화된 방식으로 웹 페이지를 방문하여 데이터를 수집하는 과정입니다. 이는 검색 엔진 최적화나 데이터 분석에 자주 사용됩니다.
예시: 구글 검색 엔진이 인터넷 상의 웹사이트를 방문하여 콘텐츠를 수집하고 인덱싱하는 것이 크롤링입니다.
연관키워드: 데이터 수집, 웹 스크래핑, 검색 엔진
Word2Vec
----------------------------------------------------------------------------------------------------
문서 4:
정의: 페이지 랭크는 웹 페이지의 중요도를 평가하는 알고리즘으로, 주로 검색 엔진 결과의 순위를 결정하는 데 사용됩니다. 이는 웹 페이지 간의 링크 구조를 분석하여 평가합니다.
예시: 구글 검색 엔진은 페이지 랭크 알고리즘을 사용하여 검색 결과의 순위를 정합니다.
연관키워드: 검색 엔진 최적화, 웹 분석, 링크 분석
데이터 마이닝
=========================================================
============== LLMChainExtractor 적용 후 ==================
문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.
결과 해석: - 기존 리트리버: 4개 문서 모두 반환 (약 800토큰) - 압축 리트리버: 관련 문서만 추출 (약 200토큰, 75% 감소) - 효과: 토큰 사용량 감소로 비용 절감, 할루시네이션 위험 감소
8 LLMChainFilter: 문서 선택 기반 필터링
LLMChainFilter는 문서 내용을 수정하지 않고 관련 문서만 선택하여 반환합니다.
from langchain_teddynote.document_compressors import LLMChainFilter # 입력쿼리와 관련된 내용만 필터링, 문서 내용 변경은 하지않음
# LLM을 사용하여 LLMChainFilter 객체를 생성
_filter = LLMChainFilter.from_llm(llm)
compression_retriever = ContextualCompressionRetriever(
# LLMChainFilter와 retriever를 사용하여 ContextualCompressionRetriever 객체를 생성
base_compressor=_filter,
base_retriever=retriever,
)
compressed_docs = compression_retriever.invoke("Semantic Search 에 대해서 알려줘.")
pretty_print_docs(compressed_docs)문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.
연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝
Embedding8.1 EmbeddingsFilter
- 각각의 검색된 문서에 대해 추가적인 LLM 호출을 수행하는 것은 비용이 많이 들고 속도가 느리다
EmbeddingsFilter는 문서와 쿼리를 임베딩하고 쿼리와 충분히 유사한 임베딩을 가진 문서만 반환함으로써 더 저렴하고 빠른 옵션을 제공- 이를 통해 검색 결과의 관련성을 유지하면서도 계산 비용과 시간을 절약
EmbeddingsFilter와ContextualCompressionRetriever를 사용하여 관련 문서를 압축하고 검색하는 과정EmbeddingsFilter를 사용하여 지정된 유사도 임계값(0.86) 이상인 문서를 필터링 합니다.
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
embeddings_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.86)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke("Semantic Search 에 대해서 알려줘.")
pretty_print_docs(compressed_docs)문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.
연관키워드: 자연어 처리, 검색 알고리즘, 데이터 마이닝
Embedding9 DocumentCompressorPipeline: 다단계 압축
여러 compressor를 순차적으로 결합하여 최적화된 결과를 얻는다
파이프라인 단계: 1. TextSplitter: 문서를 작은 청크로 분할 2. EmbeddingsRedundantFilter: 중복 문서 제거 (유사도 0.95 이상) 3. EmbeddingsFilter: 관련성 필터링 (유사도 0.86 이상) 4. LLMChainExtractor: 최종 내용 추출
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_text_splitters import CharacterTextSplitter
# 문자 기반 텍스트 분할기를 생성하고, 청크 크기를 300으로, 청크 간 중복을 0으로 설정합니다.
splitter = CharacterTextSplitter(chunk_size=300, chunk_overlap=0)
# 임베딩을 사용하여 중복 필터를 생성: 검색된 문서 사이의 유사도 검색을 수행, 0.95도 이상의 문서들은 중복 문서라 판단하고 드랍시켜줌
redundant_filter = EmbeddingsRedundantFilter(embeddings=embeddings)
# 임베딩을 사용하여 관련성 필터를 생성하고, 유사도 임계값을 0.86으로 설정합니다.
relevant_filter = EmbeddingsFilter(embeddings=embeddings, similarity_threshold=0.86)
pipeline_compressor = DocumentCompressorPipeline(
# 문서 압축 파이프라인을 생성하고, 분할기, 중복 필터, 관련성 필터, LLMChainExtractor를 변환기를 순서대로 설정합니다.
# 반드시, 이 기능들을 순서대로 쓰는게 아니라 필요시 파이프라인을 추가할 수 있다는 것에 집중
transformers=[
splitter,
redundant_filter,
relevant_filter,
LLMChainExtractor.from_llm(llm),
]
)ContextualCompressionRetriever를 초기화하며, base_compressor로 pipeline_compressor를, base_retriever로 retriever를 사용합니다.
compression_retriever = ContextualCompressionRetriever(
# 기본 압축기로 pipeline_compressor를 사용하고, 기본 검색기로 retriever를 사용하여 ContextualCompressionRetriever를 초기화
base_compressor=pipeline_compressor,
base_retriever=retriever,
)
compressed_docs = compression_retriever.invoke("Semantic Search 에 대해서 알려줘.")
pretty_print_docs(compressed_docs)문서 1:
Semantic Search
정의: 의미론적 검색은 사용자의 질의를 단순한 키워드 매칭을 넘어서 그 의미를 파악하여 관련된 결과를 반환하는 검색 방식입니다.
예시: 사용자가 "태양계 행성"이라고 검색하면, "목성", "화성" 등과 같이 관련된 행성에 대한 정보를 반환합니다.