Pinecone은 고성능 벡터 데이터베이스로, AI 및 머신러닝 애플리케이션을 위한 효율적인 벡터 저장 및 검색 솔루션입니다.
Pinecone, Chroma, Faiss와 같은 벡터 데이터베이스들을 비교해보겠습니다.
Pinecone의 장점
확장성: 대규모 데이터셋에 대해 뛰어난 확장성을 제공합니다.
관리 용이성: 완전 관리형 서비스로, 인프라 관리 부담이 적습니다.
실시간 업데이트: 데이터의 실시간 삽입, 업데이트, 삭제가 가능합니다.
고가용성: 클라우드 기반으로 높은 가용성과 내구성을 제공합니다.
API 친화적: RESTful/Python API를 통해 쉽게 통합할 수 있습니다.
Pinecone의 단점
비용: Chroma나 Faiss에 비해 상대적으로 비용이 높을 수 있습니다.
커스터마이징 제한: 완전 관리형 서비스이기 때문에 세부적인 커스터마이징에 제한이 있을 수 있습니다.
데이터 위치: 클라우드에 데이터를 저장해야 하므로, 데이터 주권 문제가 있을 수 있습니다.
Chroma나 Faiss와 비교했을 때:
- Chroma/FAISS 오픈소스이며 로컬에서 실행 가능하여 초기 비용이 낮고 데이터 제어가 용이합니다. 커스터마이징의 자유도가 높습니다. 하지만 대규모 확장성 면에서는 Pinecone에 비해 제한적일 수 있습니다.
선택은 프로젝트의 규모, 요구사항, 예산 등을 고려하여 결정해야 합니다. 대규모 프로덕션 환경에서는 Pinecone이 유리할 수 있지만, 소규모 프로젝트나 실험적인 환경에서는 Chroma나 Faiss가 더 적합할 수 있습니다.
참고
# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("CH09-VectorStores")1 업데이트 안내
아래의 기능은 커스텀 구현한 내용이므로 아래의 라이브러리를 반드시 업데이트 후 진행해야 합니다.
2 한글 처리를 위한 불용어 사전
한글 불용어 사전 가져오기 (추후 토크나이저에 사용)
3 데이터 전처리
아래는 일반 문서의 전처리 과정입니다. ROOT_DIR 하위에 있는 모든 .pdf 파일을 읽어와 document_lsit 에 저장합니다.
from langchain_community.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
import glob
# 텍스트 분할
text_splitter = RecursiveCharacterTextSplitter(chunk_size=300, chunk_overlap=50)
split_docs = []
# 텍스트 파일을 load -> List[Document] 형태로 변환
files = sorted(glob.glob("data/*.pdf"))
for file in files:
loader = PyMuPDFLoader(file)
split_docs.extend(loader.load_and_split(text_splitter))
# 문서 개수 확인
len(split_docs)Pinecone 에 DB 저장하기 위한 문서 전처리를 수행합니다. 이 과정에서 metadata_keys 를 지정할 수 있습니다.
추가로 metadata 를 태깅하고 싶은 경우 사전 처리 작업에서 미리 metadata 를 추가한 뒤 진행합니다.
split_docs: 문서 분할 결과를 담은 List[Document] 입니다.metadata_keys: 문서에 추가할 metadata 키를 담은 List 입니다.min_length: 문서의 최소 길이를 지정합니다. 이 길이보다 짧은 문서는 제외합니다.use_basename: 소스 경로를 기준으로 파일명을 사용할지 여부를 지정합니다. 기본값은False입니다.
3.1 문서의 전처리
필요한
metadata정보를 추출합니다.최소 길이 이상의 데이만 필터링 합니다.
문서의
basename을 사용할지 여부를 지정합니다. 기본값은False입니다.- 여기서
basename이란 파일 경로의 가장 마지막 부분을 의미합니다. - 예를 들어,
/Users/teddy/data/document.pdf의 경우document.pdf가 됩니다.
- 여기서
3.2 API 키 발급
- 링크
- 프로필 - Account - Projects - Starter - API keys - 발급
.env 파일에 아래와 같이 추가합니다.
PINECONE_API_KEY="YOUR_PINECONE_API_KEY"4 새로운 VectorStore 인덱스 생성
Pinecone 의 새로운 인덱스를 생성합니다.
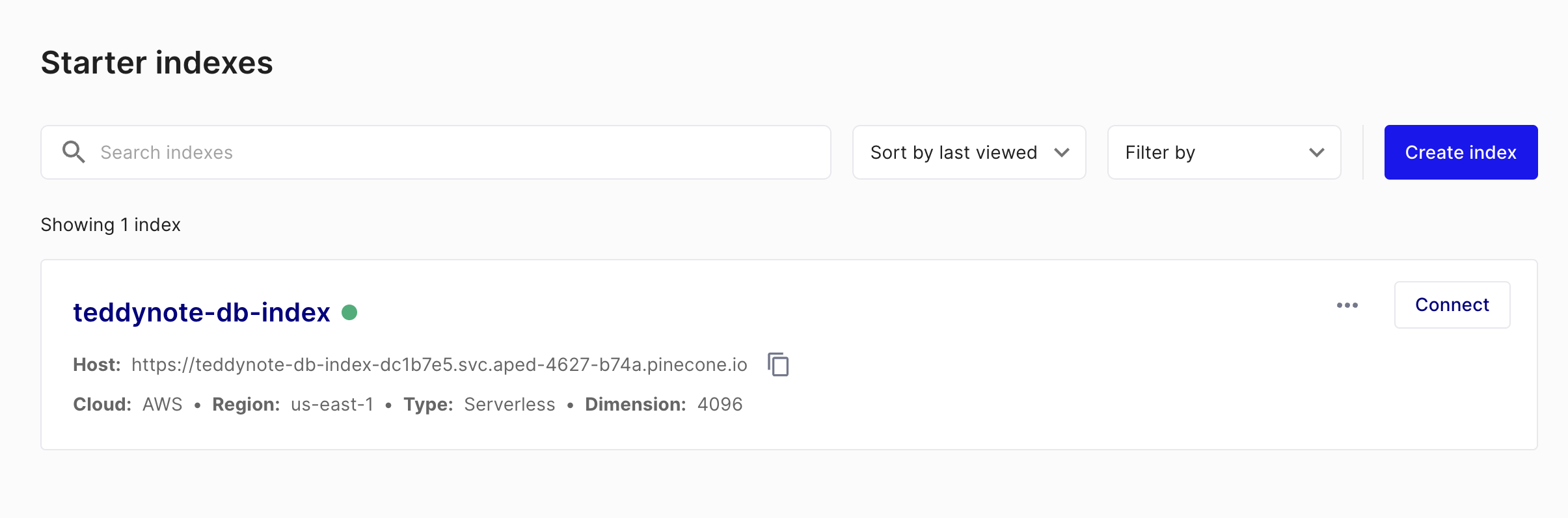
pinecone 인덱스를 생성합니다.
주의사항 - metric 은 유사도 측정 방법을 지정합니다. 만약 HybridSearch 를 고려하고 있다면 metric 은 dotproduct 로 지정합니다.
import os
from langchain_teddynote.community.pinecone import create_index
# Pinecone 인덱스 생성
pc_index = create_index(
api_key=os.environ["PINECONE_API_KEY"],
index_name="teddynote-db-index", # 인덱스 이름을 지정합니다.
dimension=4096, # Embedding 차원과 맞춥니다. (OpenAIEmbeddings: 1536, UpstageEmbeddings: 4096)
metric="dotproduct", # 유사도 측정 방법을 지정합니다. (dotproduct, euclidean, cosine)
)아래는 유료 Pod 를 사용하는 예시입니다. 유료 Pod 는 무료 Serverless Pod 대비 더 확장된 기능을 제공합니다.
- 참고: https://docs.pinecone.io/guides/indexes/choose-a-pod-type-and-size
import os
from langchain_teddynote.community.pinecone import create_index
from pinecone import PodSpec
# Pinecone 인덱스 생성
pc_index = create_index(
api_key=os.environ["PINECONE_API_KEY"],
index_name="teddynote-db-index2", # 인덱스 이름을 지정합니다.
dimension=4096, # Embedding 차원과 맞춥니다. (OpenAIEmbeddings: 1536, UpstageEmbeddings: 4096)
metric="dotproduct", # 유사도 측정 방법을 지정합니다. (dotproduct, euclidean, cosine)
pod_spec=PodSpec(
environment="us-west1-gcp", pod_type="p1.x1", pods=1
), # 유료 Pod 사용
)5 Sparse Encoder 생성
- Sparse Encoder 를 생성합니다.
Kiwi Tokenizer와 한글 불용어(stopwords) 처리를 수행합니다.- Sparse Encoder 를 활용하여 contents 를 학습합니다. 여기서 학습한 인코드는 VectorStore 에 문서를 저장할 때 Sparse Vector 를 생성할 때 활용합니다.
from langchain_teddynote.community.pinecone import (
create_sparse_encoder,
fit_sparse_encoder,
)
# 한글 불용어 사전 + Kiwi 형태소 분석기를 사용합니다.
sparse_encoder = create_sparse_encoder(stopwords(), mode="kiwi")Sparse Encoder 에 Corpus 를 학습합니다.
save_path: Sparse Encoder 를 저장할 경로입니다. 추후에pickle형식으로 저장한 Sparse Encoder 를 불러와 Query 임베딩할 때 사용합니다. 따라서, 이를 저장할 경로를 지정합니다.
# Sparse Encoder 를 사용하여 contents 를 학습
saved_path = fit_sparse_encoder(
sparse_encoder=sparse_encoder, contents=contents, save_path="./sparse_encoder.pkl"
)[선택사항] 아래는 나중에 학습하고 저장한 Sparse Encoder 를 다시 불러와야 할 때 사용하는 코드입니다.
from langchain_teddynote.community.pinecone import load_sparse_encoder
# 추후에 학습된 sparse encoder 를 불러올 때 사용합니다.
sparse_encoder = load_sparse_encoder("./sparse_encoder.pkl")5.1 Pinecone: DB Index에 추가 (Upsert)
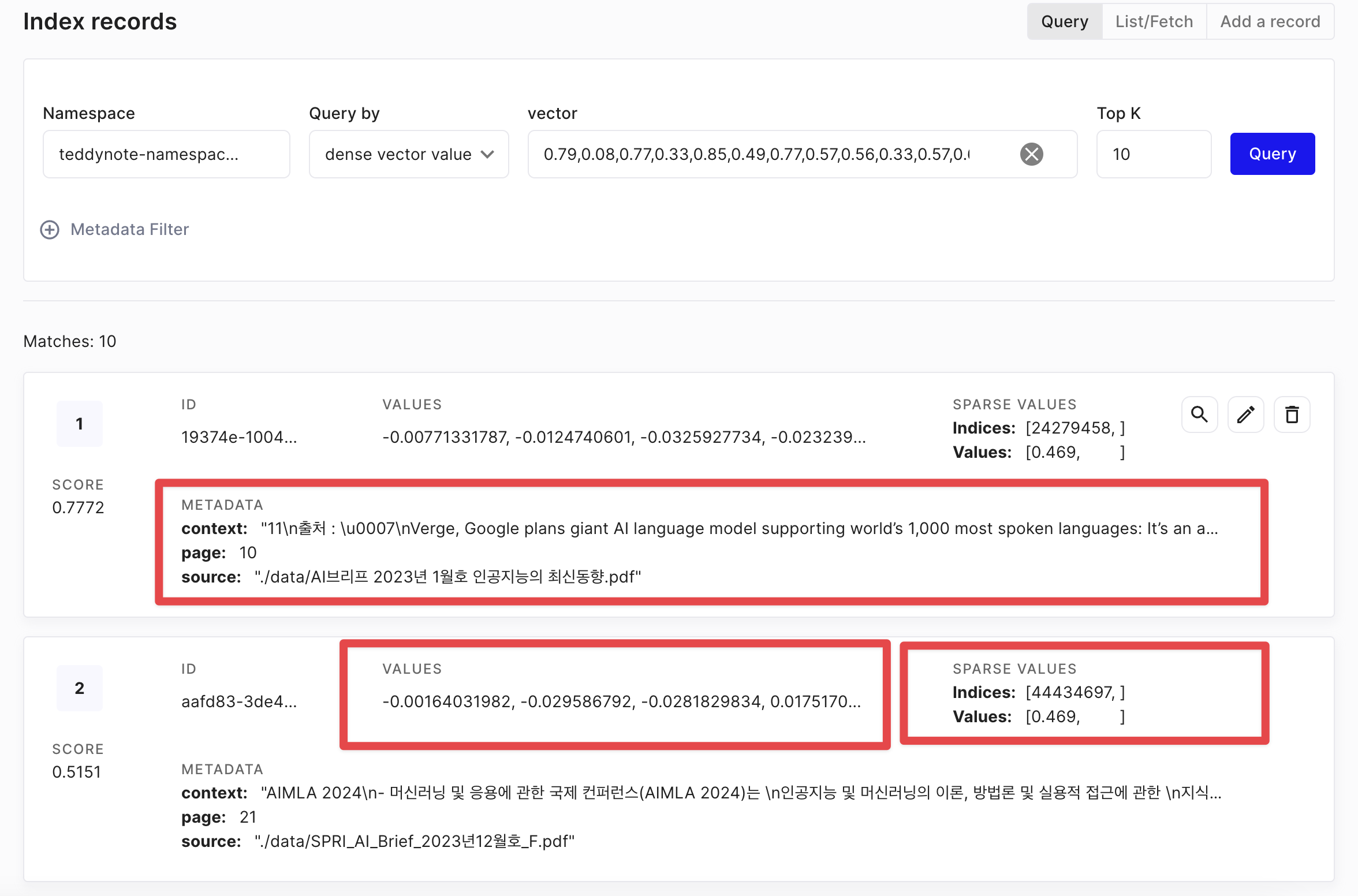
context: 문서의 내용입니다.page: 문서의 페이지 번호입니다.source: 문서의 출처입니다.values: Embedder 를 통해 얻은 문서의 임베딩입니다.sparse values: Sparse Encoder 를 통해 얻은 문서의 임베딩입니다.
from langchain_openai import OpenAIEmbeddings
from langchain_upstage import UpstageEmbeddings
# 임베딩 모델 생성
openai_embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
upstage_embeddings = UpstageEmbeddings(model="solar-embedding-1-large-passage")분산 처리를 하지 않고 배치 단위로 문서를 Upsert 합니다. 문서의 양이 많지 않다면 아래의 방식을 사용하세요.
%%time
from langchain_teddynote.community.pinecone import upsert_documents
from langchain_upstage import UpstageEmbeddings
upsert_documents(
index=pc_index, # Pinecone 인덱스
namespace="teddynote-namespace-01", # Pinecone namespace
contents=contents, # 이전에 전처리한 문서 내용
metadatas=metadatas, # 이전에 전처리한 문서 메타데이터
sparse_encoder=sparse_encoder, # Sparse encoder
embedder=upstage_embeddings,
batch_size=32,
)아래는 분산처리를 수행하여 대용량 문서를 빠르게 Upsert 합니다. 대용량 업로드시 활용하세요.
%%time
from langchain_teddynote.community.pinecone import upsert_documents_parallel
upsert_documents_parallel(
index=pc_index, # Pinecone 인덱스
namespace="teddynote-namespace-02", # Pinecone namespace
contents=contents, # 이전에 전처리한 문서 내용
metadatas=metadatas, # 이전에 전처리한 문서 메타데이터
sparse_encoder=sparse_encoder, # Sparse encoder
embedder=upstage_embeddings,
batch_size=64,
max_workers=30,
)6 인덱스 조회/삭제
describe_index_stats 메서드는 인덱스의 내용에 대한 통계 정보를 제공합니다. 이 메서드를 통해 네임스페이스별 벡터 수와 차원 수 등의 정보를 얻을 수 있습니다.
매개변수 * filter (Optional[Dict[str, Union[str, float, int, bool, List, dict]]]): 특정 조건에 맞는 벡터들에 대한 통계만 반환하도록 하는 필터. 기본값은 None * **kwargs: 추가 키워드 인자
반환값 * DescribeIndexStatsResponse: 인덱스에 대한 통계 정보를 담고 있는 객체
사용 예시 * 기본 사용: index.describe_index_stats() * 필터 적용: index.describe_index_stats(filter={'key': 'value'})
참고 - metadata 필터링은 유료 사용자에 한하여 가능합니다.
6.1 네임스페이스(namespace) 삭제
from langchain_teddynote.community.pinecone import delete_namespace
delete_namespace(
pinecone_index=pc_index,
namespace="teddynote-namespace-01",
)아래는 유료 사용자 전용 기능입니다. 유료 사용자는 metadata 필터링을 사용할 수 있습니다.
7 검색기(Retriever) 생성
7.1 PineconeKiwiHybridRetriever 초기화 파라미터 설정
init_pinecone_index 함수와 PineconeKiwiHybridRetriever 클래스는 Pinecone을 사용한 하이브리드 검색 시스템을 구현합니다. 이 시스템은 밀집 벡터와 희소 벡터를 결합하여 효과적인 문서 검색을 수행합니다.
Pinecone 인덱스 초기화
init_pinecone_index 함수는 Pinecone 인덱스를 초기화하고 필요한 구성 요소를 설정합니다.
매개변수 * index_name (str): Pinecone 인덱스 이름 * namespace (str): 사용할 네임스페이스 * api_key (str): Pinecone API 키 * sparse_encoder_pkl_path (str): 희소 인코더 피클 파일 경로 * stopwords (List[str]): 불용어 리스트 * tokenizer (str): 사용할 토크나이저 (기본값: “kiwi”) * embeddings (Embeddings): 임베딩 모델 * top_k (int): 반환할 최대 문서 수 (기본값: 10) * alpha (float): 밀집 벡터와 희소 벡터의 가중치 조절 파라미터 (기본값: 0.5)
주요 기능 1. Pinecone 인덱스 초기화 및 통계 정보 출력 2. 희소 인코더(BM25) 로딩 및 토크나이저 설정 3. 네임스페이스 지정
import os
from langchain_teddynote.korean import stopwords
from langchain_teddynote.community.pinecone import init_pinecone_index
from langchain_upstage import UpstageEmbeddings
pinecone_params = init_pinecone_index(
index_name="teddynote-db-index", # Pinecone 인덱스 이름
namespace="teddynote-namespace-02", # Pinecone Namespace
api_key=os.environ["PINECONE_API_KEY"], # Pinecone API Key
sparse_encoder_path="./sparse_encoder.pkl", # Sparse Encoder 저장경로(save_path)
stopwords=stopwords(), # 불용어 사전
tokenizer="kiwi",
embeddings=UpstageEmbeddings(
model="solar-embedding-1-large-query"
), # Dense Embedder
top_k=5, # Top-K 문서 반환 개수
alpha=0.5, # alpha=0.75로 설정한 경우, (0.75: Dense Embedding, 0.25: Sparse Embedding)
)7.2 PineconeKiwiHybridRetriever
PineconeKiwiHybridRetriever 클래스는 Pinecone과 Kiwi를 결합한 하이브리드 검색기를 구현합니다.
주요 속성 * embeddings: 밀집 벡터 변환용 임베딩 모델 * sparse_encoder: 희소 벡터 변환용 인코더 * index: Pinecone 인덱스 객체 * top_k: 반환할 최대 문서 수 * alpha: 밀집 벡터와 희소 벡터의 가중치 조절 파라미터 * namespace: Pinecone 인덱스 내 네임스페이스
특징 * 밀집 벡터와 희소 벡터를 결합한 HybridSearch Retriever * 가중치 조절을 통한 검색 전략 최적화 가능 * 다양한 동적 metadata 필터링 적용 가능(search_kwargs 사용: filter, k, rerank, rerank_model, top_n 등)
사용 예시 1. init_pinecone_index 함수로 필요한 구성 요소 초기화 2. 초기화된 구성 요소로 PineconeKiwiHybridRetriever 인스턴스 생성 3. 생성된 검색기를 사용하여 하이브리드 검색 수행
PineconeKiwiHybridRetriever 를 생성합니다.
from langchain_teddynote.community.pinecone import PineconeKiwiHybridRetriever
# 검색기 생성
pinecone_retriever = PineconeKiwiHybridRetriever(**pinecone_params)일반 검색
# 실행 결과
search_results = pinecone_retriever.invoke("gpt-4o 미니 출시 관련 정보에 대해서 알려줘")
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n====================\n")동적 search_kwargs 사용 - k: 반환할 최대 문서 수 지정
# 실행 결과
search_results = pinecone_retriever.invoke(
"gpt-4o 미니 출시 관련 정보에 대해서 알려줘", search_kwargs={"k": 1}
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n====================\n")동적 search_kwargs 사용 - alpha: 밀집 벡터와 희소 벡터의 가중치 조절 파라미터. 0과 1 사이의 값을 지정합니다. 0.5 가 기본값이고, 1에 가까울수록 dense 벡터의 가중치가 높아집니다.
# 실행 결과
search_results = pinecone_retriever.invoke(
"앤스로픽", search_kwargs={"alpha": 1, "k": 1}
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n====================\n")# 실행 결과
search_results = pinecone_retriever.invoke(
"앤스로픽", search_kwargs={"alpha": 0, "k": 1}
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n====================\n")Metadata 필터링
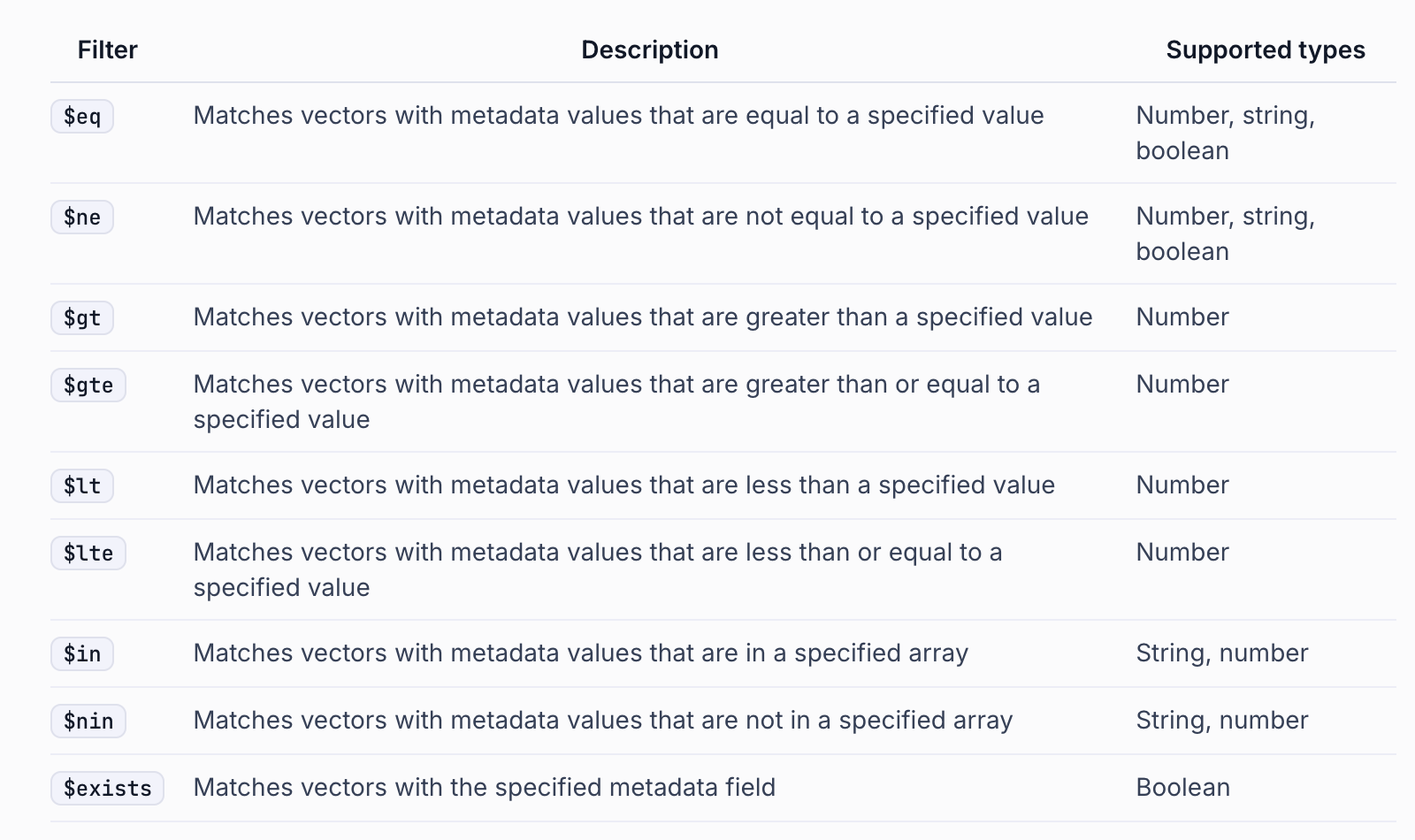
동적 search_kwargs 사용 - filter: metadata 필터링 적용
(예시) page 가 5보다 작은 문서만 검색합니다.
# 실행 결과
search_results = pinecone_retriever.invoke(
"앤스로픽의 claude 출시 관련 내용을 알려줘",
search_kwargs={"filter": {"page": {"$lt": 5}}, "k": 2},
)
for result in search_results:
print(result.page_content)
print(result.metadata)
print("\n====================\n")동적 search_kwargs 사용 - filter: metadata 필터링 적용
(예시) source 가 SPRi AI Brief_8월호_산업동향.pdf 문서내 검색합니다.
8 Reranking 적용
- 동적 reranking 기능을 구현해 놓았지만, pinecone 라이브러리 의존성에 문제가 있을 수 있습니다.
- 따라서, 아래 코드는 향후 의존성 해결 후 원활하게 동작할 수 있습니다.
참고 문서: https://docs.pinecone.io/guides/inference/rerank
# reranker 미사용
retrieval_results = pinecone_retriever.invoke(
"앤스로픽의 클로드 소넷",
)
# BGE-reranker-v2-m3 모델 사용
reranked_results = pinecone_retriever.invoke(
"앤스로픽의 클로드 소넷",
search_kwargs={"rerank": True, "rerank_model": "bge-reranker-v2-m3", "top_n": 3},
)# retrieval_results 와 reranked_results 를 비교합니다.
for res1, res2 in zip(retrieval_results, reranked_results):
print("[Retrieval]")
print(res1.page_content)
print("\n------------------\n")
print("[Reranked] rerank_score: ", res2.metadata["rerank_score"])
print(res2.page_content)
print("\n====================\n")