# LangSmith 추적을 설정합니다. https://smith.langchain.com
# !pip install langchain-teddynote
from langchain_teddynote import logging
# 프로젝트 이름을 입력합니다.
logging.langsmith("CH08-Embeddings")import os
import warnings
# 경고 무시
warnings.filterwarnings("ignore")
# ./cache/ 경로에 다운로드 받도록 설정
os.environ["HF_HOME"] = "./cache/"1 샘플 데이터
texts = [
"안녕, 만나서 반가워.",
"LangChain simplifies the process of building applications with large language models",
"랭체인 한국어 튜토리얼은 LangChain의 공식 문서, cookbook 및 다양한 실용 예제를 바탕으로 하여 사용자가 LangChain을 더 쉽고 효과적으로 활용할 수 있도록 구성되어 있습니다. ",
"LangChain은 초거대 언어모델로 애플리케이션을 구축하는 과정을 단순화합니다.",
"Retrieval-Augmented Generation (RAG) is an effective technique for improving AI responses.",
]참고(Reference)
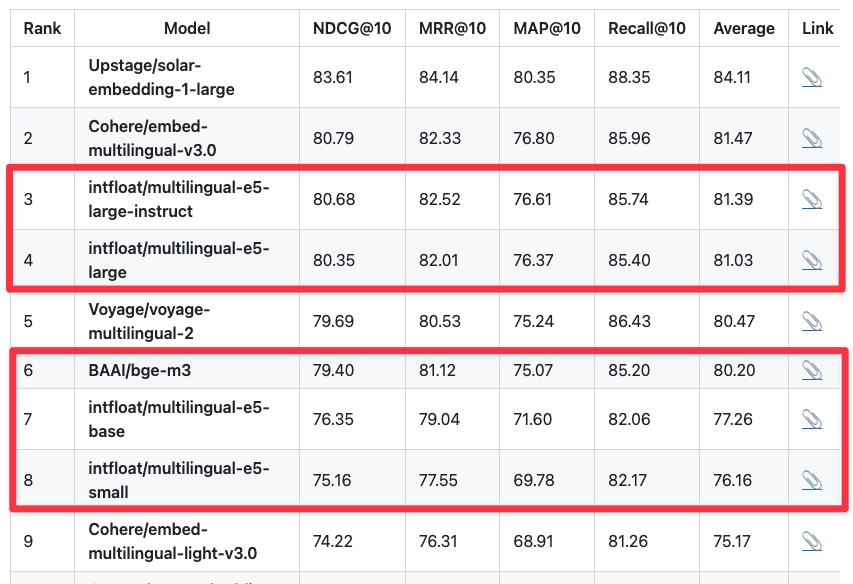
2 HuggingFace Endpoint Embedding
HuggingFaceEndpointEmbeddings 는 내부적으로 InferenceClient를 사용하여 임베딩을 계산한다는 점에서 HuggingFaceEndpoint가 LLM에서 수행하는 것과 매우 유사합니다.
from langchain_huggingface.embeddings import HuggingFaceEndpointEmbeddings
model_name = "intfloat/multilingual-e5-large-instruct"
hf_embeddings = HuggingFaceEndpointEmbeddings(
model=model_name,
task="feature-extraction",
huggingfacehub_api_token=os.environ["HUGGINGFACEHUB_API_TOKEN"],
)Document 임베딩은 embed_documents() 를 호출하여 생성할 수 있습니다.
print("[HuggingFace Endpoint Embedding]")
print(f"Model: \t\t{model_name}")
print(f"Dimension: \t{len(embedded_documents[0])}")2.1 유사도 계산
벡터 내적을 통한 유사도 계산 - 벡터 내적(dot product)을 사용하여 유사도를 계산합니다.
- 유사도 계산 공식:
\[ \text{similarities} = \mathbf{query} \cdot \mathbf{documents}^T \]
2.1.1 벡터 내적의 수학적 의미
벡터 내적 정의
벡터 \(\mathbf{a}\)와 \(\mathbf{b}\)의 내적은 다음과 같이 정의됩니다: \[ \mathbf{a} \cdot \mathbf{b} = \sum_{i=1}^{n} a_i b_i \]
코사인 유사도와의 관계
벡터 내적은 다음과 같은 성질을 가집니다. \[ \mathbf{a} \cdot \mathbf{b} = \|\mathbf{a}\| \|\mathbf{b}\| \cos \theta \]
여기서, - \(\|\mathbf{a}\|\)와 \(\|\mathbf{b}\|\)는 각각 벡터 \(\mathbf{a}\)와 \(\mathbf{b}\)의 크기(노름, Euclidean norm)입니다. - \(\theta\)는 두 벡터 사이의 각도입니다. - \(\cos \theta\)는 두 벡터 사이의 코사인 유사도입니다.
벡터 내적의 유사도 해석 내적 값이 클수록 (양의 큰 값일수록), - 두 벡터의 크기(\(\|\mathbf{a}\|\)와 \(\|\mathbf{b}\|\))가 크고, - 두 벡터 사이의 각도(\(\theta\))가 작으며 (\(\cos \theta\)가 1에 가까움),
이는 두 벡터가 유사한 방향을 가리키고, 크기가 클수록 더 유사하다는 것을 의미합니다.
벡터의 크기(노름) 계산
Euclidean norm 정의 벡터 \(\mathbf{a} = [a_1, a_2, \ldots, a_n]\)에 대해, Euclidean norm \(\|\mathbf{a}\|\)는 다음과 같이 정의됩니다: \[ \|\mathbf{a}\| = \sqrt{a_1^2 + a_2^2 + \cdots + a_n^2} \]
query 와 embedding_document 간의 유사도 계산
3 HuggingFace Embeddings
3.1 intfloat/multilingual-e5-large-instruct
from langchain_huggingface.embeddings import HuggingFaceEmbeddings
model_name = "intfloat/multilingual-e5-large-instruct"
# model_name = "intfloat/multilingual-e5-large"
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs={"device": "mps"}, # cuda, cpu
encode_kwargs={"normalize_embeddings": True},
)4 BGE-M3 임베딩
아래의 옵션 중 에러가 발생할 수 있는 옵션 설명
{"device": "mps"}: GPU 대신 MPS를 사용하여 임베딩 계산을 수행합니다. (Mac 사용자){"device": "cuda"}: GPU를 사용하여 임베딩 계산을 수행합니다. (Linux, Windows 사용자, 단 CUDA 설치 필요){"device": "cpu"}: CPU를 사용하여 임베딩 계산을 수행합니다. (모든 사용자
from langchain_huggingface import HuggingFaceEmbeddings
model_name = "BAAI/bge-m3"
model_kwargs = {"device": "mps"}
encode_kwargs = {"normalize_embeddings": True}
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name, model_kwargs=model_kwargs, encode_kwargs=encode_kwargs
)import numpy as np
embedded_query = hf_embeddings.embed_query("LangChain 에 대해서 알려주세요.")
embedded_documents = hf_embeddings.embed_documents(texts)
# 질문(embedded_query): LangChain 에 대해서 알려주세요.
np.array(embedded_query) @ np.array(embedded_documents).T
sorted_idx = (np.array(embedded_query) @ np.array(embedded_documents).T).argsort()[::-1]
print("[Query] LangChain 에 대해서 알려주세요.\n====================================")
for i, idx in enumerate(sorted_idx):
print(f"[{i}] {texts[idx]}")
print()4.1 FlagEmbedding 을 활용하는 방식
참고 - FlagEmbedding - BGE-M3 Usage
FlagEmbedding 에서 제공하는 세 가지 접근법을 조합하면, 더욱 강력한 검색 시스템을 구축할 수 있습니다.
- Dense Vector: BGE-M3의 다국어, 다중 작업 능력을 기반으로 함
- Lexical weight를 활용한 sparse embedding으로 정확한 단어 매칭을 수행
- ColBERT의 multi-vector 접근법으로 문맥을 고려한 세밀한 매칭 수행
from FlagEmbedding import BGEM3FlagModel
model_name = "BAAI/bge-m3"
bge_embeddings = BGEM3FlagModel(
model_name, use_fp16=True
) # use_fp16을 True로 설정하면 약간의 성능 저하와 함께 계산 속도가 빨라집니다.
bge_embedded = bge_embeddings.encode(
texts,
batch_size=12,
max_length=8192, # 이렇게 긴 길이가 필요하지 않은 경우 더 작은 값을 설정하여 인코딩 프로세스의 속도를 높일 수 있습니다.
)["dense_vecs"]4.2 Sparse Embedding (Lexical Weight)
Sparse embedding은 벡터의 대부분의 값이 0인 고차원 벡터를 사용하는 임베딩 방식입니다. Lexical weight를 활용한 방식은 단어의 중요도를 고려하여 임베딩을 생성합니다.
작동 방식 1. 각 단어에 대해 lexical weight(어휘적 가중치)를 계산합니다. 이는 TF-IDF나 BM25 같은 방법을 사용할 수 있습니다. 2. 문서나 쿼리의 각 단어에 대해, 해당 단어의 lexical weight를 사용하여 sparse vector의 해당 차원에 값을 할당합니다. 3. 결과적으로 문서나 쿼리는 대부분의 값이 0인 고차원 벡터로 표현됩니다.
장점 - 단어의 중요도를 직접적으로 반영할 수 있습니다. - 특정 단어나 구문을 정확히 매칭할 수 있습니다. - 계산이 상대적으로 빠릅니다.
bge_flagmodel = BGEM3FlagModel(
"BAAI/bge-m3", use_fp16=True
) # use_fp16을 True로 설정하면 약간의 성능 저하와 함께 계산 속도가 빨라집니다.
bge_encoded = bge_flagmodel.encode(texts, return_sparse=True)lexical_scores1 = bge_flagmodel.compute_lexical_matching_score(
bge_encoded["lexical_weights"][0], bge_encoded["lexical_weights"][0]
)
lexical_scores2 = bge_flagmodel.compute_lexical_matching_score(
bge_encoded["lexical_weights"][0], bge_encoded["lexical_weights"][1]
)
# 0 <-> 0
print(lexical_scores1)
# 0 <-> 1
print(lexical_scores2)4.3 Multi-Vector (ColBERT)
ColBERT(Contextualized Late Interaction over BERT)는 문서 검색을 위한 효율적인 방법입니다. 이 방식은 문서와 쿼리를 여러 개의 벡터로 표현하는 multi-vector 접근법을 사용합니다.
작동 방식
- 문서의 각 토큰에 대해 별도의 벡터를 생성합니다. 즉, 하나의 문서는 여러 개의 벡터로 표현됩니다.
- 쿼리도 마찬가지로 각 토큰에 대해 별도의 벡터를 생성합니다.
- 검색 시, 쿼리의 각 토큰 벡터와 문서의 모든 토큰 벡터 사이의 유사도를 계산합니다.
- 이 유사도들을 종합하여 최종 검색 점수를 계산합니다.
장점 - 토큰 수준의 세밀한 매칭이 가능합니다. - 문맥을 고려한 임베딩을 생성할 수 있습니다. - 긴 문서에 대해서도 효과적으로 작동합니다.